Azkaban的使用
1、使用Flow1.0(比较老旧)
需要注意的点:
1. azkaban的job流文件,后缀是.job 1) type属性 必须赋值 值有:command,java,pig 2. azkaban执行的job必须要提前打包,打包的格式必须是zip格式 不能打包文件夹,打包文件 3. 流文件里的书写格式: 1)一定要注意行末不要有空格 2)编码集的问题,如果在window上实在不行,可以上传到linux进行zip压缩,然后下载到windows上,再上传到azkaban上
先在我们的azkaban上创建一个项目:
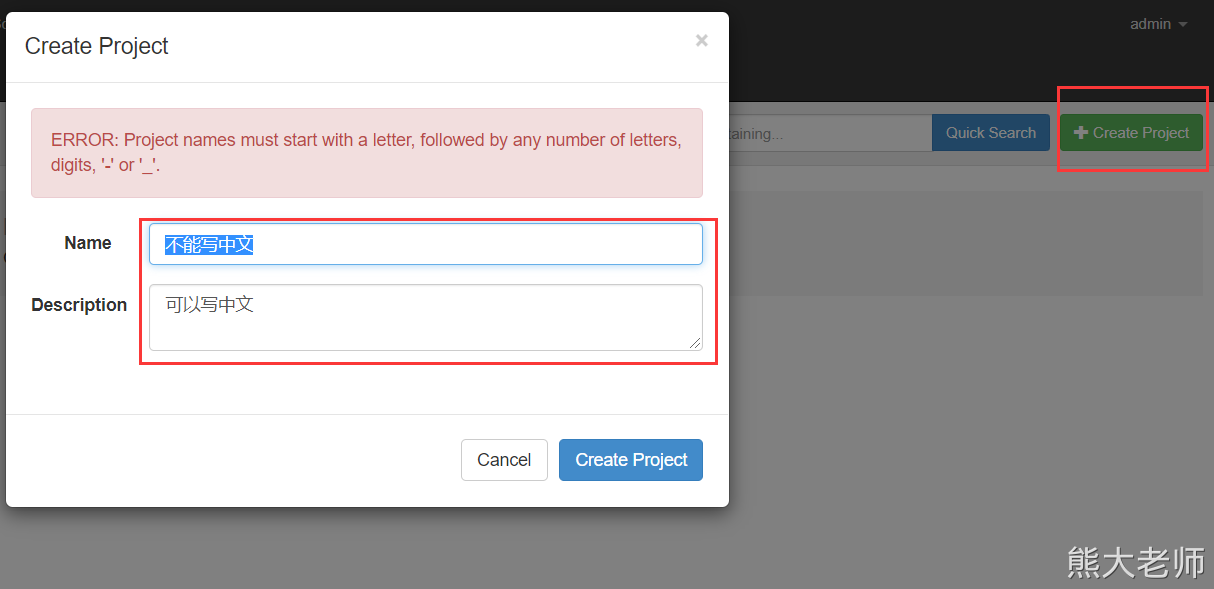
Name 不能是中文的
Description 不能为空,可以是中文
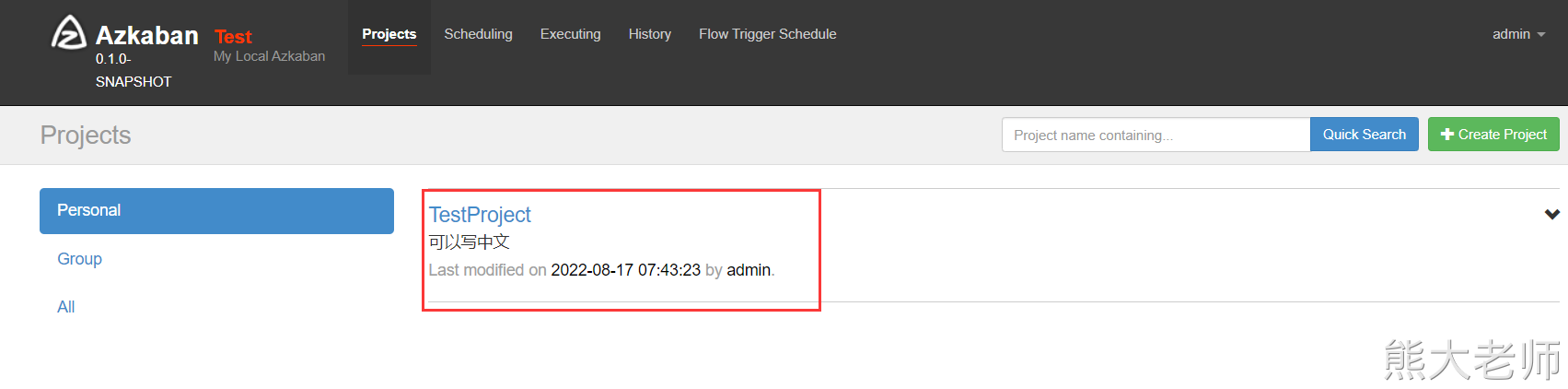
编写一个job任务:
type=command command=echo "hello world"
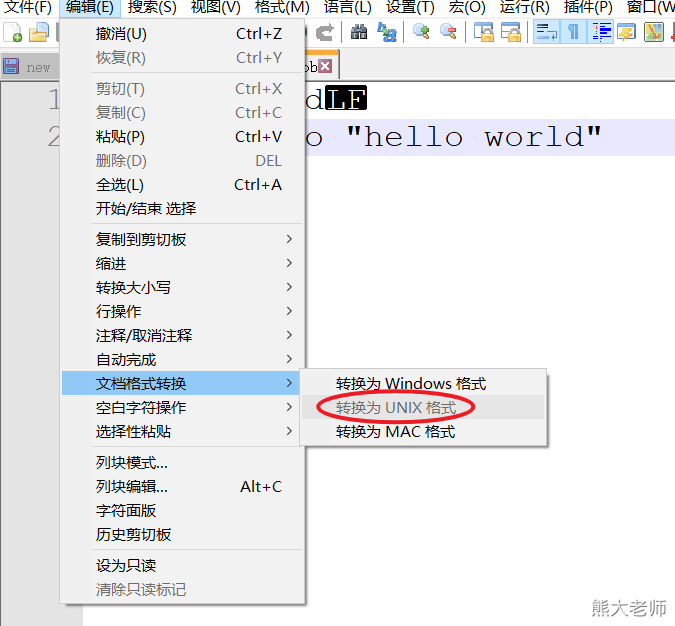
使用windows编辑这个文件的时候,一般要注意,格式,需要是unix:
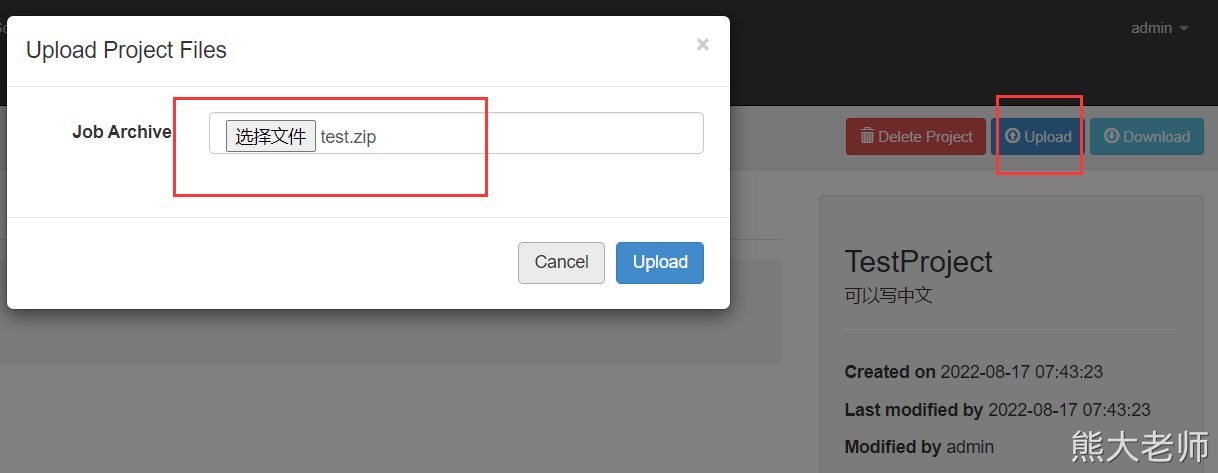
对这个hello.job 进行打包,不要打包文件夹,格式必须是zip格式
打成zip 包
上传至项目中:

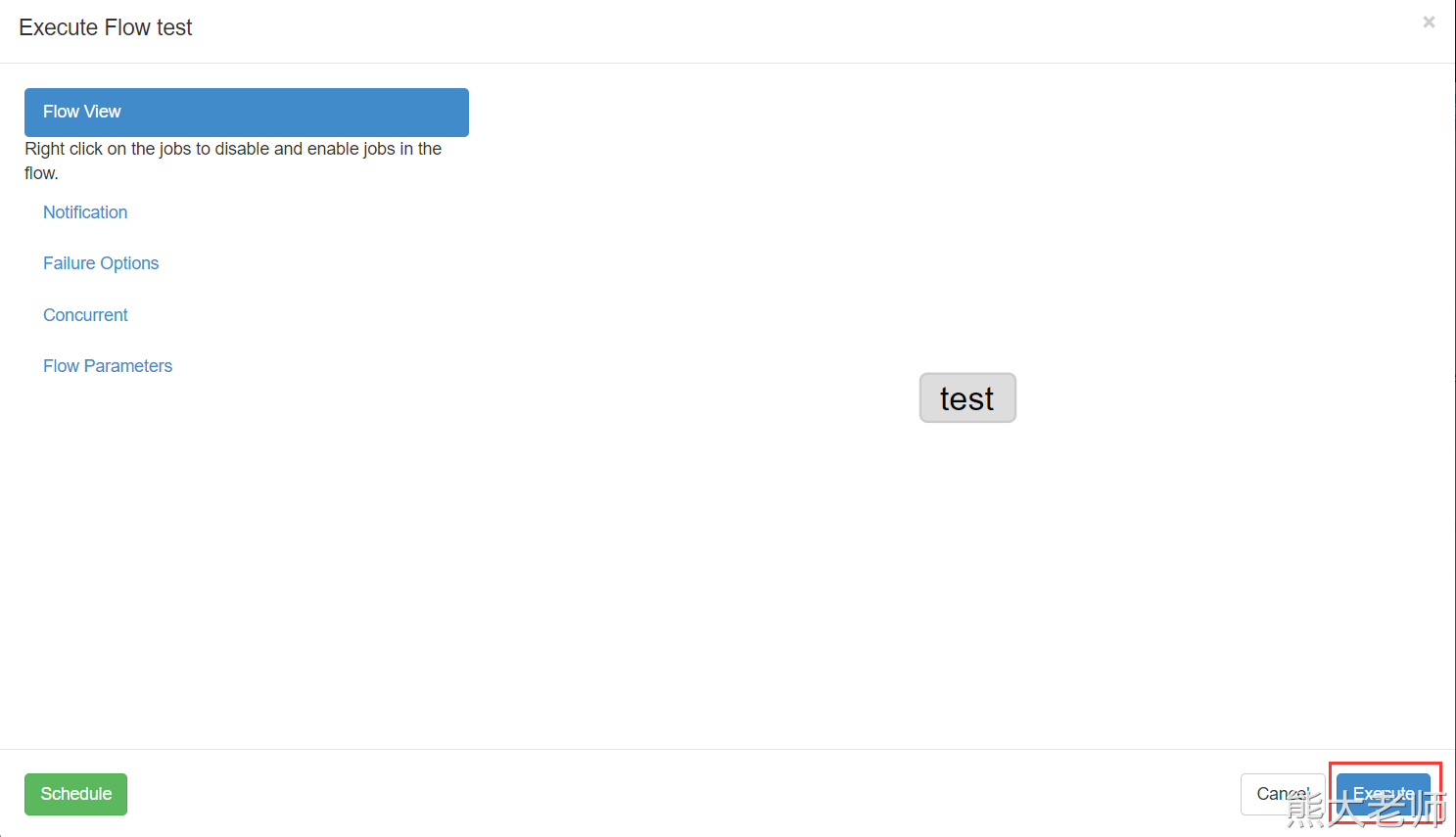
执行的时候报了错:
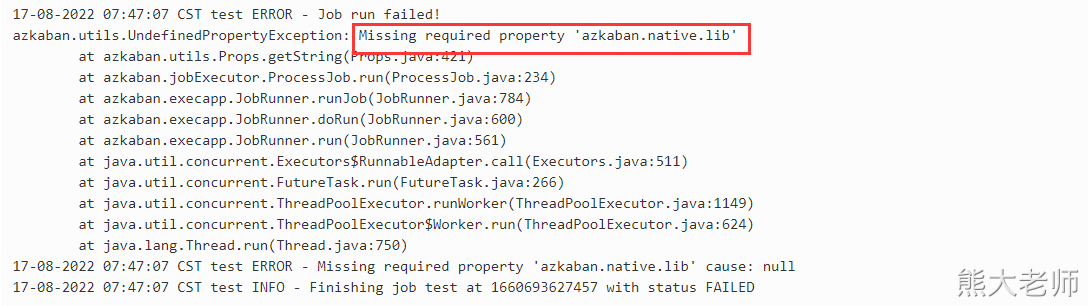
进行如下修复:
在exec-server中,修改配置文件 azkaban.proerties 添加如下代码,注意安装路径
azkaban.jobtype.plugin.dir=/opt/installs/azkaban/exec-server/plugins/jobtypes
重启exec-server即可。

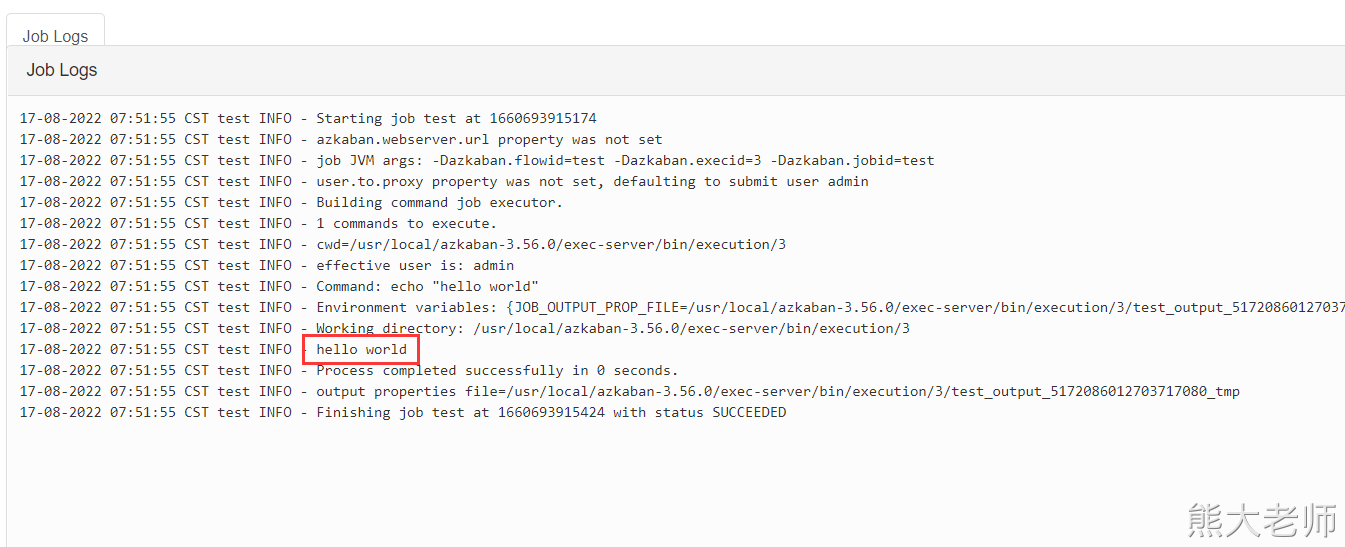
从这个里面是不是可以看到一个任务,被调用了。
通过案例可以看到:我们可以将编写好的shell,以及mr任务,以及定时任务以及hive脚本都可以写成job任务,让azkaban帮助我们调度。
2、Flow2.0的用法
1、小试牛刀
需要创建两个文件 JobA.flow JobA.project
在JobA.project中编写一句话:
azkaban-flow-version: 2.0
在JobA.flow中,编写任务,需要注意YAML语句:
nodes: - name: jobA type: command config: command: echo "this is a simple test"
打包两个文件到一个zip中

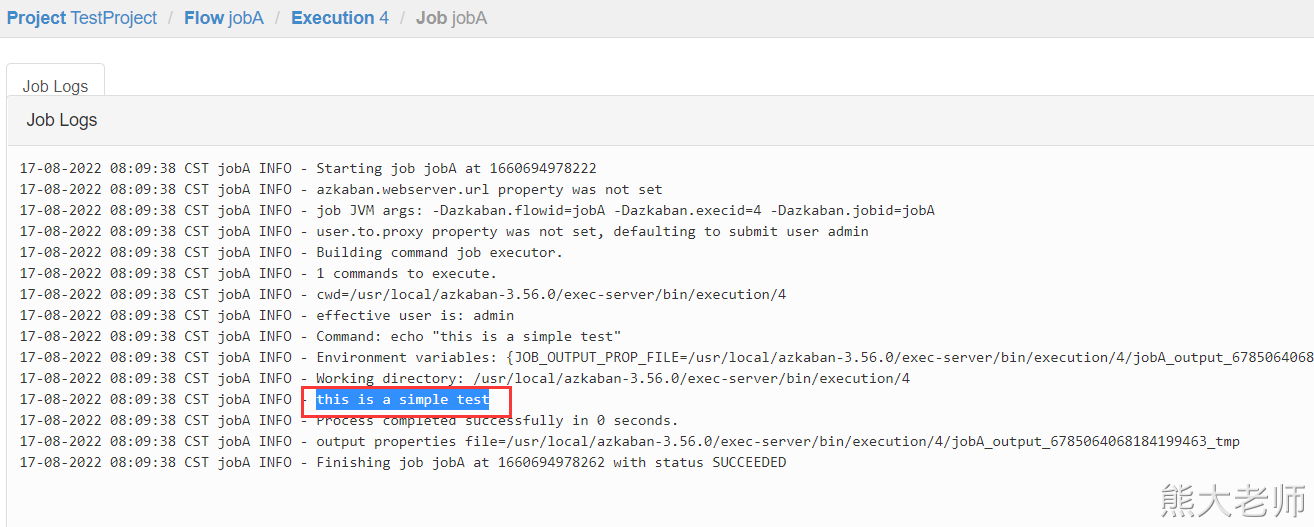
2、YAML格式的数据
听说过JSON、XML,后来出现YAML,作用跟json和xml是一样的都是一种文件,可以传递信息。
JSON 和 XML 都是用来存储和传输数据的。
JSON 存储数据,比如 datax中大量使用了json
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"age"
],
"splitPk": "id",
"connection": [
{
"table": [
"user"
],
"jdbcUrl": [
"jdbc:mysql://192.168.52.12:3306/sqoop"
]
}
]
}
}
编写好了一个json ,里面含有大量的信息,肯定是有人用了。用的人肯定解析了这个文件。
JSON 传输数据: html --> Java(SSM SSH SpringBoot)
xml 也可以做到。但是慢慢的淘汰了。
这三类文件格式都可以充当配置文件(存储数据)
JSON: core.json
XML : hdfs-site.xml
YAML : 即将开始比如SpringBoot 里面支持两种配置文件:application.properties 和 application.yaml
1. 大小写敏感 2. 使用缩进表示层级关系 ; 3. 缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级; 4. 使用#表示注释 ; 5. 字符串默认不用加单双引号,但单引号和双引号都可以使用,双引号表示不需要对特殊字符进行转义; 6. YAML 中提供了多种常量结构,包括:整数,浮点数,字符串,NULL,日期,布尔,时间。 7、缩进不允许使用tab,只允许空格
语法格式:
# value 与 : 符号之间必须要有一个空格 key: value
# 写法一 同一缩进的所有键值对属于一个map
key:
key1: value1
key2: value2
# 写法二
{key1: value1, key2: value2}# 写法一 使用一个短横线加一个空格代表一个数组项 - a - b - c # 写法二 [a,b,c]
s1: '内容\n 字符串'
s2: "内容\n 字符串"
转换后:
{ s1: '内容\\n 字符串', s2: "内容\n 字符串" }
如果你想表示一个换行:
s1: "内容\n 字符串"Flow 2.0 建议将公共参数定义在 `config` 下,并通过 `${}` 进行引用。yaml 是这两年非常流行的数据格式,书写格式要求很严格,层级关系纯靠缩进进行表示。
3、多任务依赖
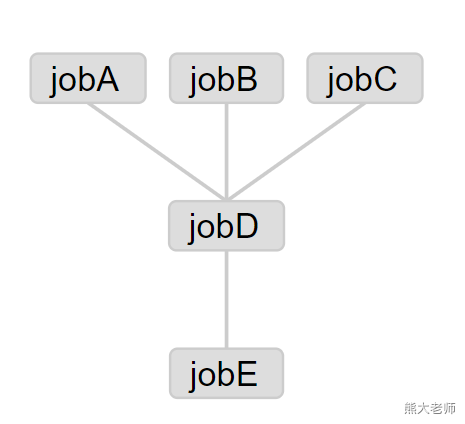
nodes: - name: jobE type: command config: command: echo "This is job E" # jobE depends on jobD dependsOn: - jobD - name: jobD type: command config: command: echo "This is job D" # jobD depends on jobA、jobB、jobC dependsOn: - jobA - jobB - jobC - name: jobA type: command config: command: echo "This is job A" - name: jobB type: command config: command: echo "This is job B" - name: jobC type: command config: command: echo "This is job C"
azkaban-flow-version: 2.0
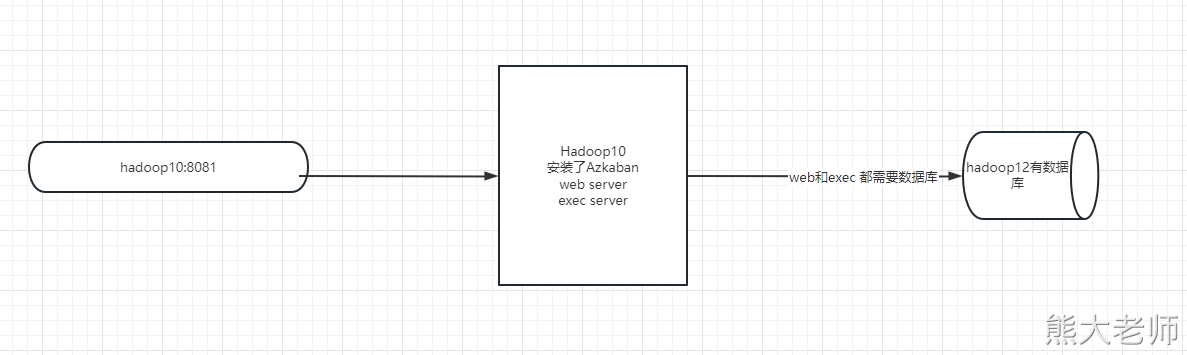
复习一下昨天的安装:
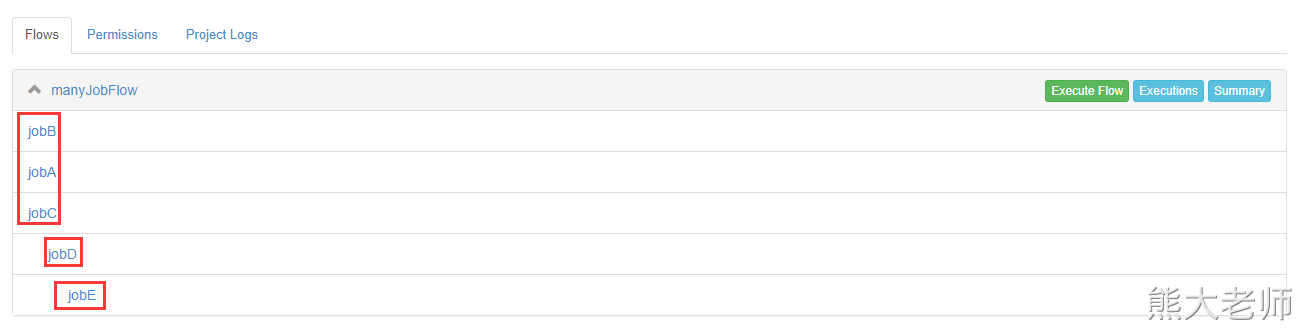
可以一次执行多个任务,也可以单独执行某个任务:


总结:多任务编排,靠dependsOn 这个属性。
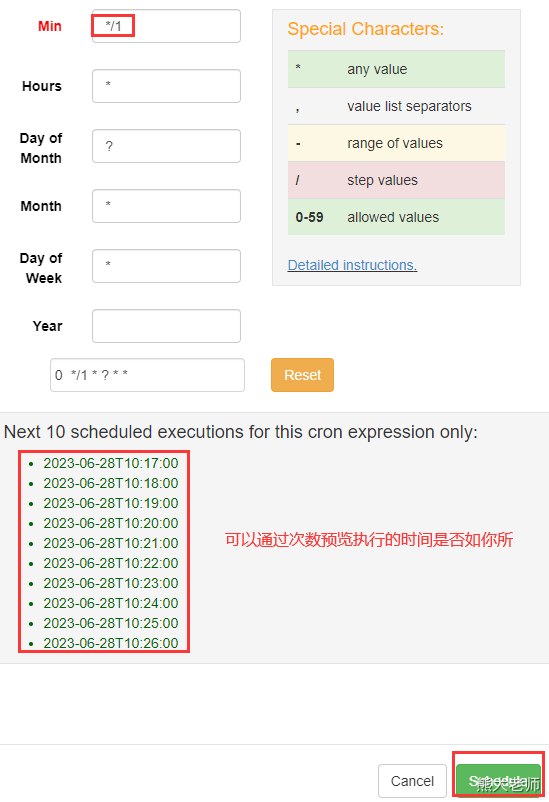
定时任务:
实战:将我们刚才的多任务的job,定时执行:

4、内嵌流(嵌套流)案例
Azkaban中一个流可以包含其他的流,方便分组和排序,也方便协作 因为在工作过程中不一定azkaban是你一个人在用,假如你的同事已经写好了好几个流,你需要放入到你的流文件中,可以直接copy,不需要修改其他的。

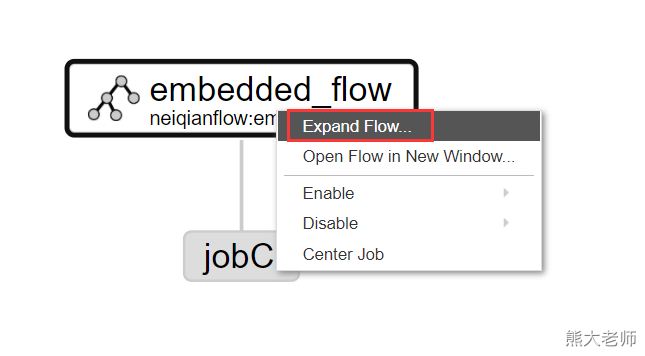
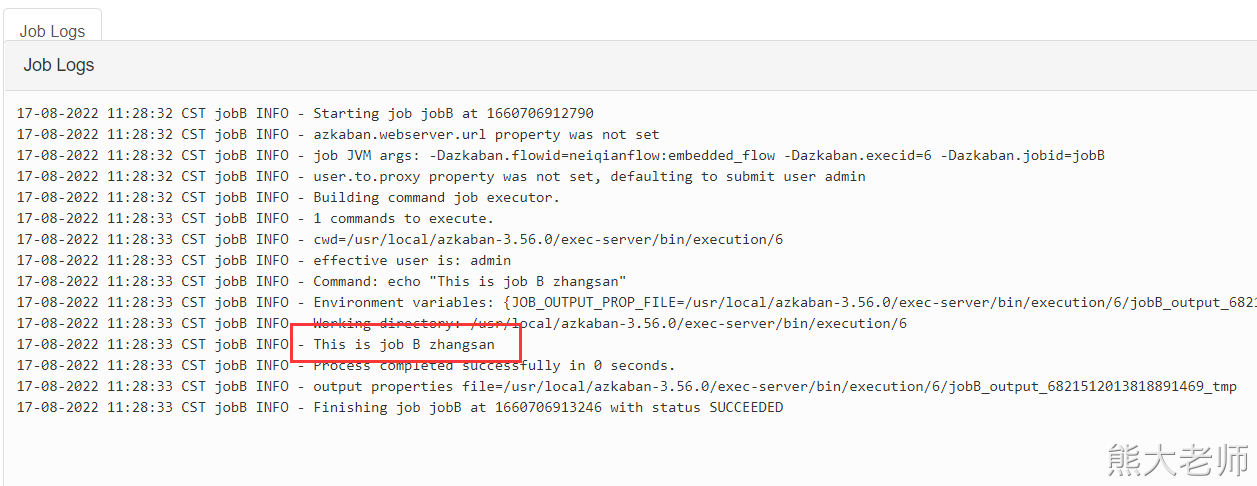
不带参数传递的内嵌流的使用:
nodes: - name: jobC type: command config: command: echo "This is job C" dependsOn: - embedded_flow - name: embedded_flow type: flow nodes: - name: jobB type: command config: command: echo "This is job B" dependsOn: - jobA - name: jobA type: command config: command: echo "This is job A"
带有参数的内嵌流:
nodes:
- name: jobC
type: command
config:
command: echo "This is job C"
dependsOn:
- embedded_flow
- name: embedded_flow
type: flow
config:
name: zhangsan
nodes:
- name: jobB
type: command
config:
command: echo "This is job B ${name}"
dependsOn:
- jobA
- name: jobA
type: command
config:
command: echo "This is job A"azkaban-flow-version: 2.0
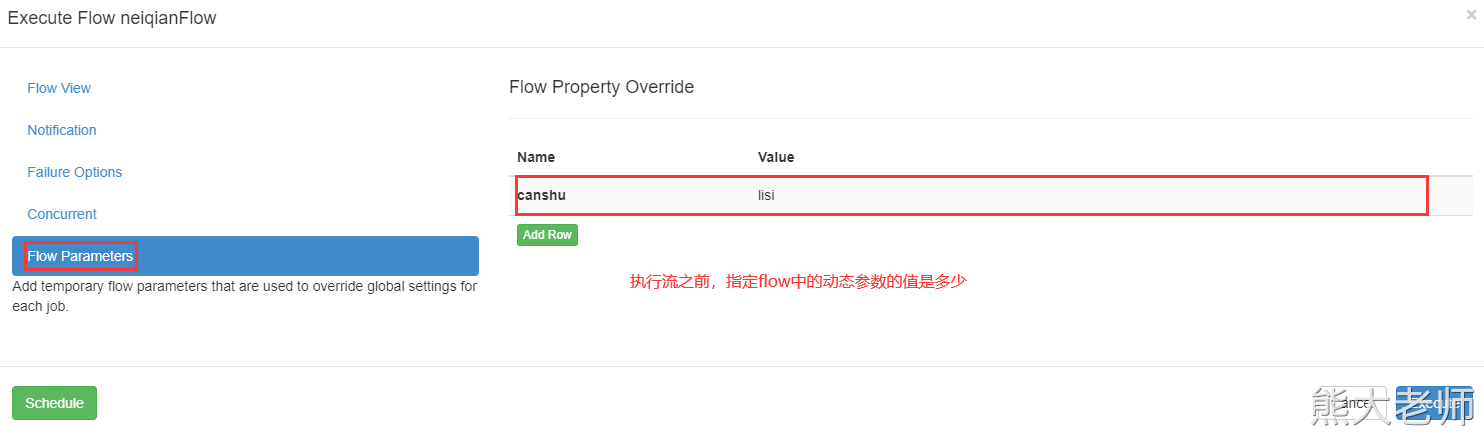
5、动态传参
代码演示:
nodes:
- name: jobC
type: command
config:
command: echo "This is job C"
dependsOn:
- test_flow
- name: test_flow
#此处是type=flow
type: flow
config:
prop: ${canshu}
#此处有nodes
nodes:
- name: jobB
type: command
config:
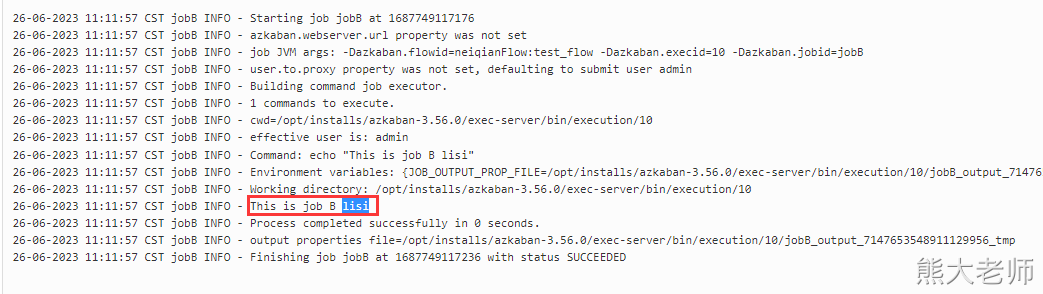
command: echo "This is job B ${prop}"
dependsOn:
- jobA
- name: jobA
type: command
config:
command: echo "This is job A"打包,上传


3、Azkaban的报警机制
1)邮箱通知
必须有一个邮箱服务器,你想接受一个邮件,肯定是另一个邮箱给你发送的。
Gmail 邮箱 谷歌的 注册一个邮箱吧
163 126 yeah 都是 163 的
名片上印上你的邮箱
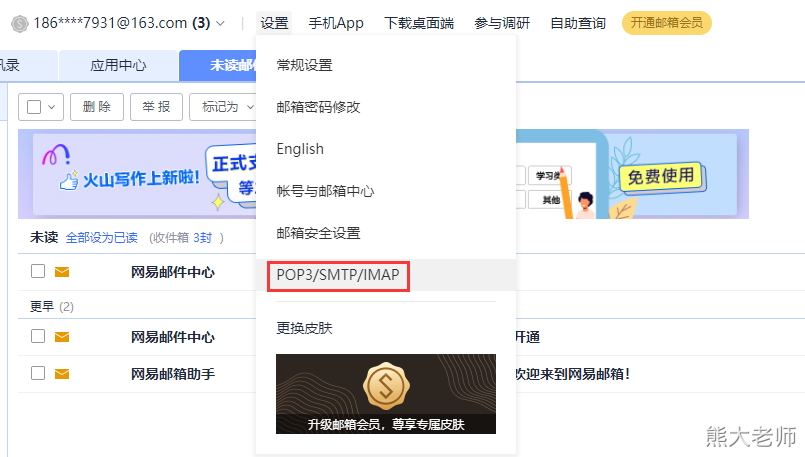
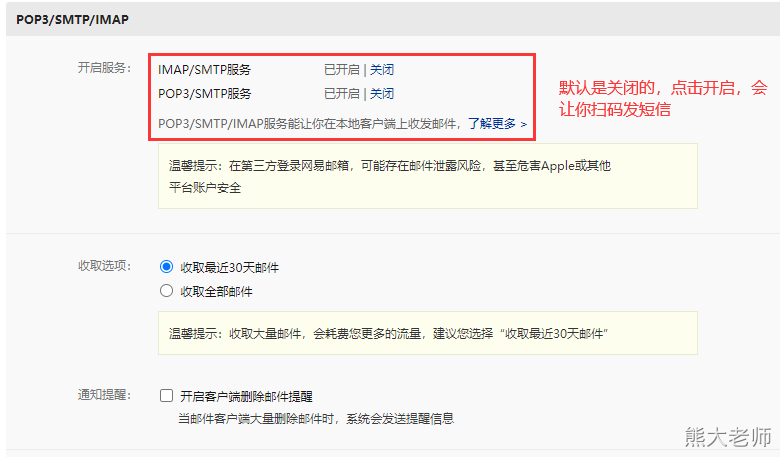
163授权码:TXSZGKKOLTMZYWCF
接着进行配置:在azkaban的 web-server 端,进行邮箱的配置:
mail.sender=18638147931@163.com mail.host=smtp.163.com mail.user=18638147931@163.com mail.password=TXSZGKKOLTMZYWCF
qq授权码:wqxyyrsontccbbfa
mail.sender=838700991@qq.com mail.host=smtp.qq.com mail.user=838700991@qq.com mail.password=wqxyyrsontccbbfa
重启web-server服务。
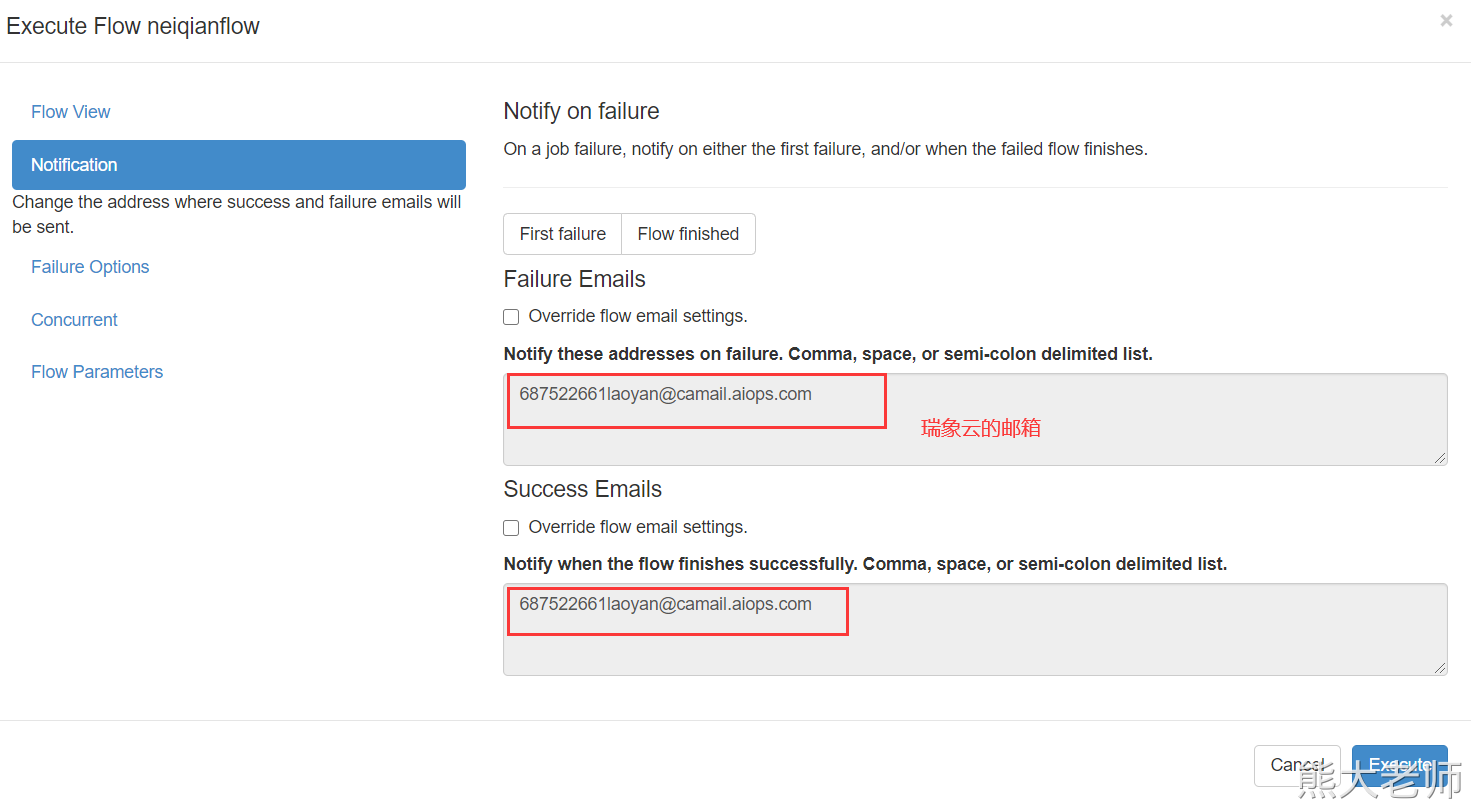
执行一个任务的时候,就可以设置要接受的邮箱地址了。
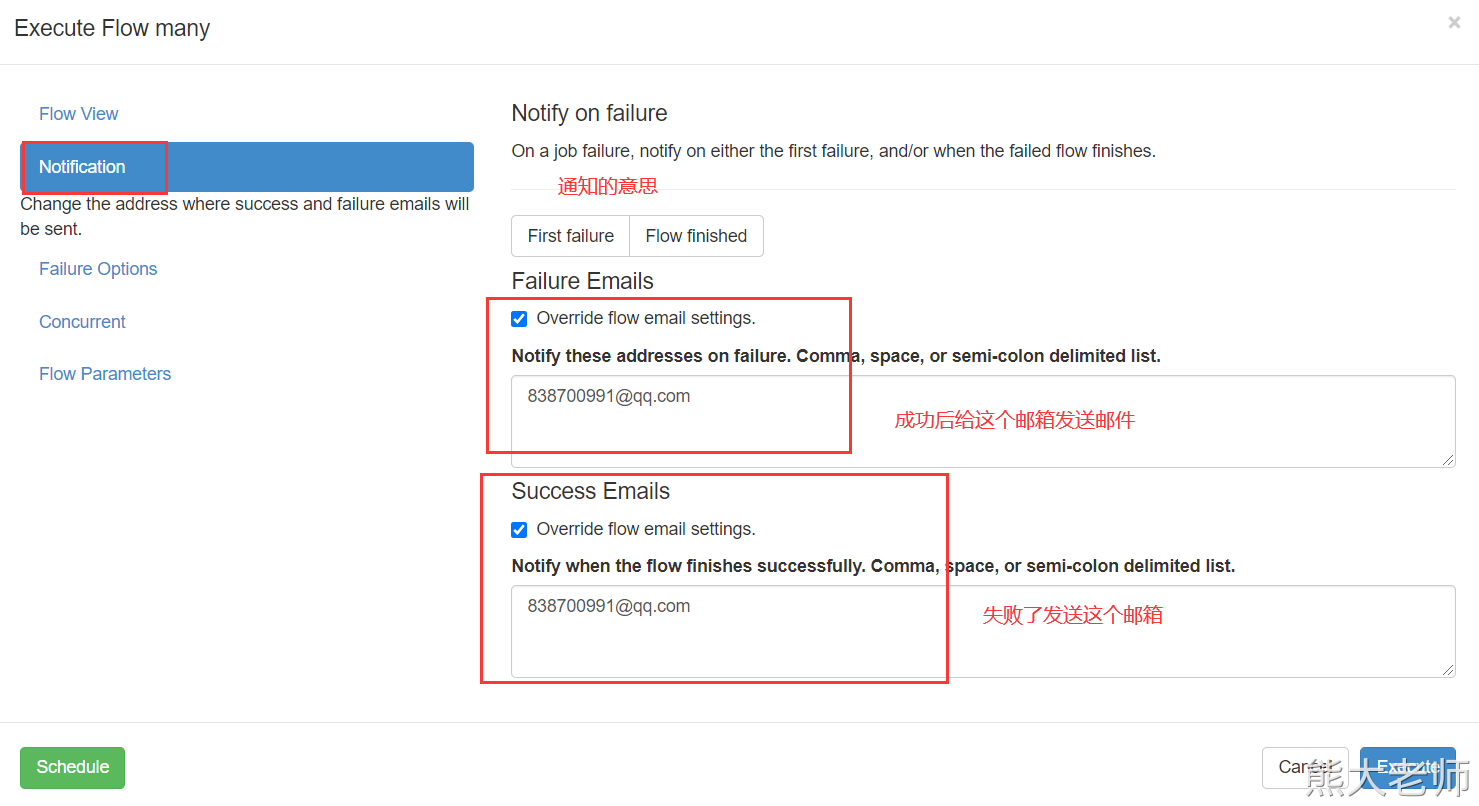
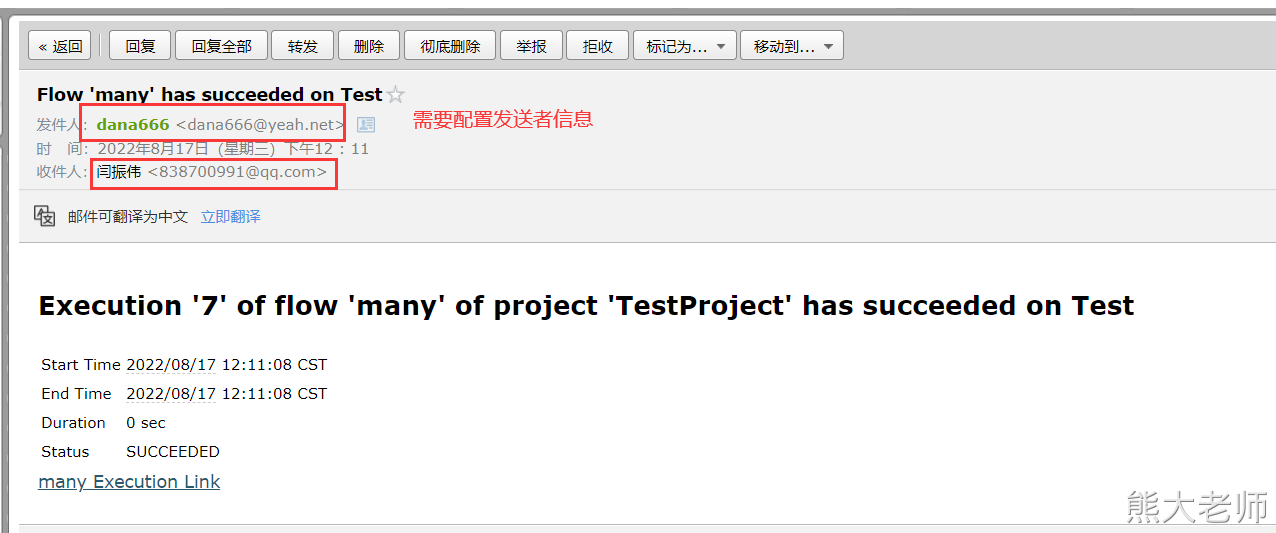
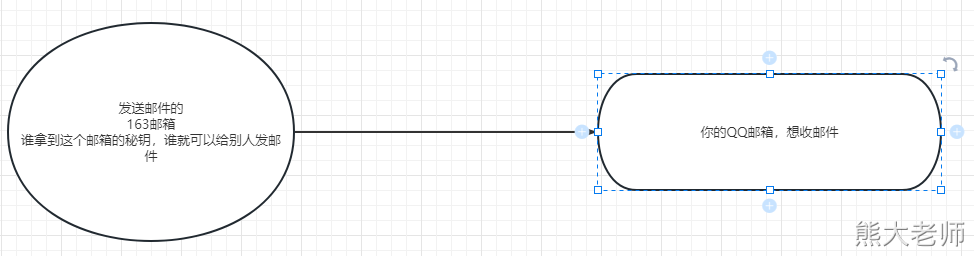
2)电话报警机制
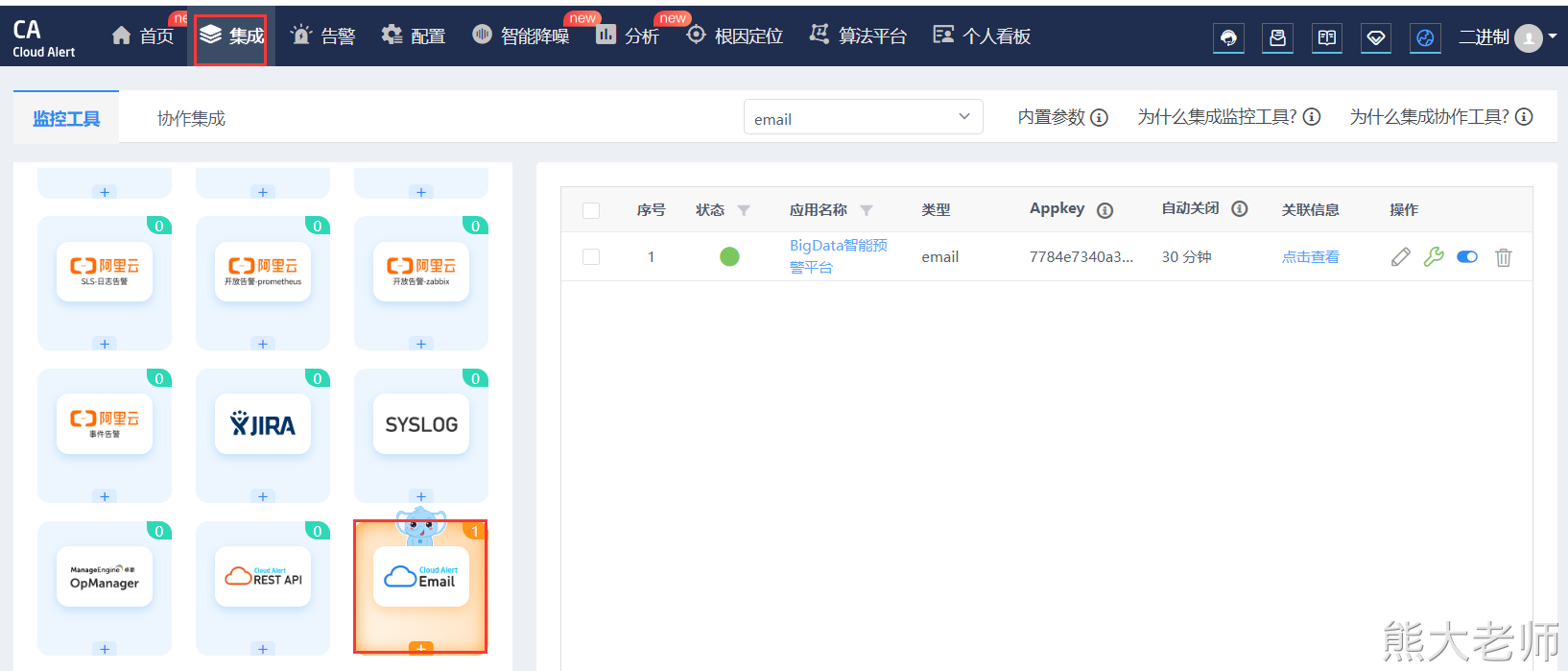
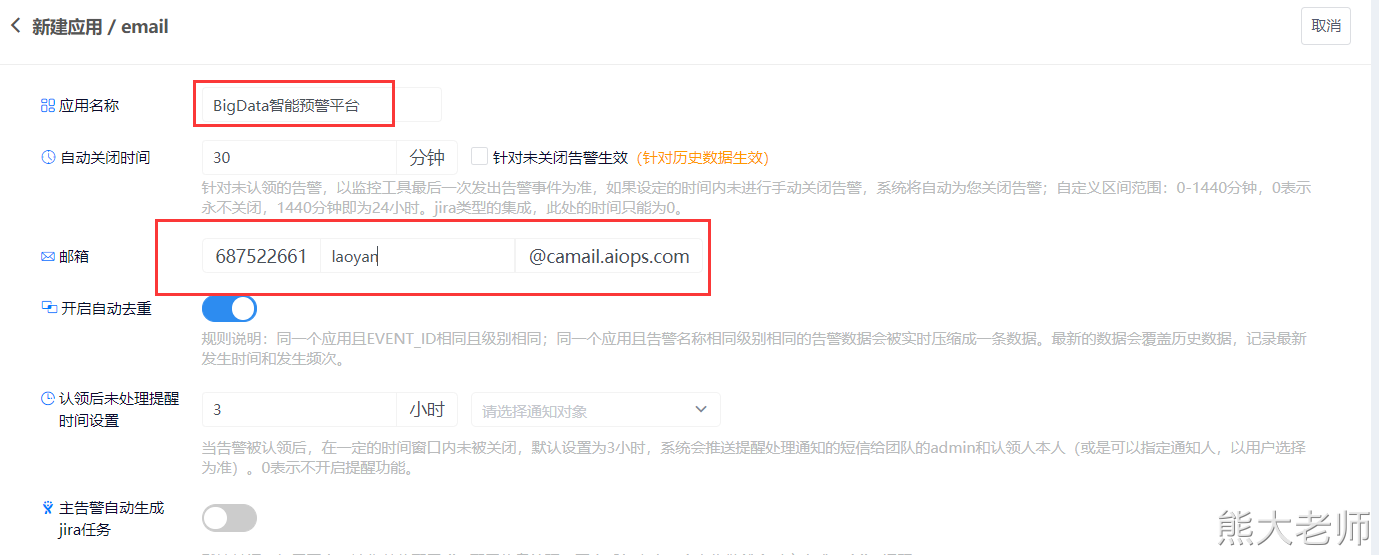
会生成一个appKey:
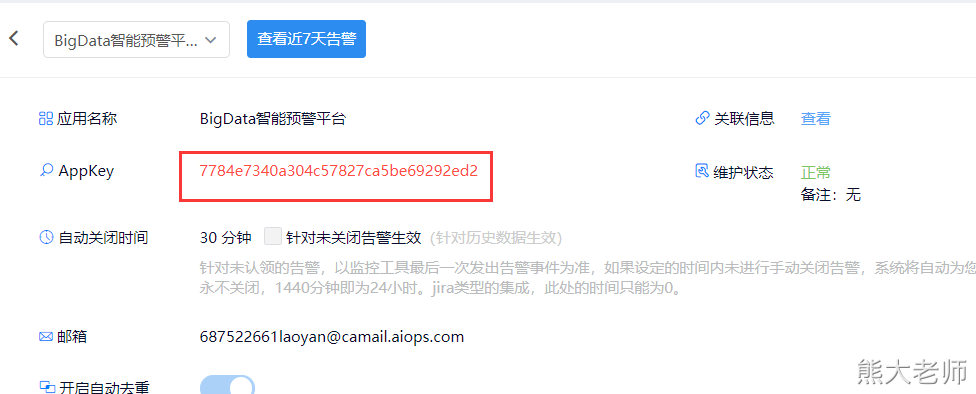

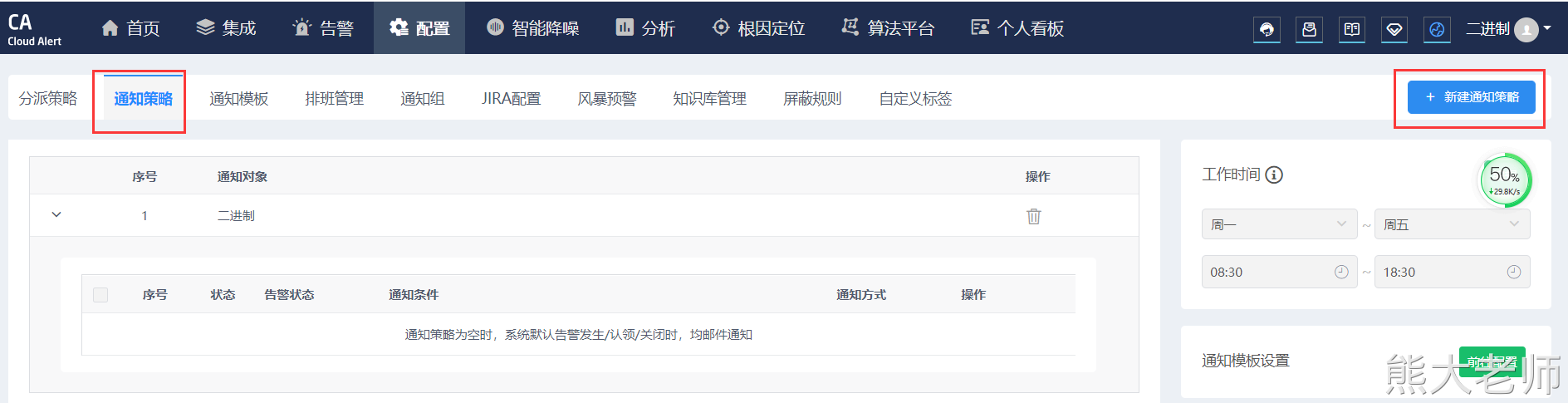

最后一个Azkaban的重试机制:
# 重试次数 retries: 3 # 每次重试时间间隔 retry.backoff: 10000 案例: nodes: - name: jobA type: command config: command: echo "this is a simple test" retries: 3 retry.backoff: 10000
4、关于azkaban脚本优化的问题
目前遇到的问题: 1、启动azkaban的时候,需要启动两个甚至多个脚本,比较麻烦 start-web.sh start-exec.sh 2、日志查看没有放在一块,需要切换目录比较麻烦 优化方案: 编写一个脚本 azkaban.sh
源码如下:
#!/bin/bash
# 参数个数一个或者两个 not equal to --> ne
if [ $# -lt 1 ] && [ $# -gt 2 ]
then
echo -e "\033[32mUsage1:\033[0m azkaban.sh 1 \033[32mor\033[0m azkaban.sh 0"
echo -e "\033[32mUsage2:\033[0m azkaban.sh 1 w \033[32mor\033[0m azkaban.sh 0 w"
exit;
fi
# 输入 1 为启动, 输入 0 为关闭
v1="web"
v2="exec"
if [ $1 -eq 1 ]
then
stat="start-"
elif [ $1 -eq 0 ]
then
stat="shutdown-"
else
echo -e "\033[32mUsage:\033[0m azkaban.sh 1 \033[32mor\033[0m azkaban.sh 0"
exit;
fi
cd /opt/installs/azkaban/logs
# 传入第二个参数 w 代表 web-server , e 代表 exec-server 不传第二个默认全部启动/停止
if [ "$2" = 'w' ]
then
path1=/opt/installs/azkaban/${v1}-server/bin/${stat}${v1}.sh
echo -e "\033[32m${stat}${v1}.sh\033[0m"
sh ${path1}
elif [ "$2" = 'e' ]
then
path2=/opt/installs/azkaban/${v2}-server/bin/${stat}${v2}.sh
echo -e "\033[32m${stat}${v2}.sh\033[0m"
sh ${path2}
elif [ 'a'"$2"'a' = 'aa' ]
then
path1=/opt/installs/azkaban/${v1}-server/bin/${stat}${v1}.sh
echo -e "\033[32m${stat}${v1}.sh\033[0m"
sh ${path1}
sleep 2
path2=/opt/installs/azkaban/${v2}-server/bin/${stat}${v2}.sh
echo -e "\033[32m${stat}${v2}.sh\033[0m"
sh ${path2}
else
echo -e "\033[32mUsage1:\033[0m azkaban.sh 1 w \033[32mor\033[0m azkaban.sh 0 w"
echo -e "\033[32mUsage2:\033[0m azkaban.sh 1 e \033[32mor\033[0m azkaban.sh 0 e"
exit;
fi
sleep 2
echo -e "\033[32m-------------------jps--------------------\033[0m"
jps配置脚本:
cd /usr/local/bin 将脚本放入进去 chmod 777 azkaban.sh
创建logs目录:
cd /opt/installs/azkaban/ 用于存储两个服务的日志 mkdir logs
使用:
# 使用方法 # 1.启动azkaban [root@hadoop10 ~]# azkaban.sh 1 # 单独启动Web [root@hadoop10 ~]# azkaban.sh 1 w # 单独启动exec [root@hadoop10 ~]# azkaban.sh 1 e # 2.关闭azkaban [root@hadoop10 ~]# azkaban.sh 0 # 单独关闭Web [root@hadoop10 ~]# azkaban.sh 0 w # 单独关闭exec [root@hadoop10 ~]# azkaban.sh 0 e