Kettle精讲
一、kettle简介
1. kettle的发展史
Kettle最早是一个开源的ETL工具,全称为KDE Extraction, Transportation, Transformation and Loading Environment。KDE源于最开始的计划是在K Desktop Environment(www.kde.org)上开发这个软件,但这个计划被取消。在2006年,Pentaho公司收购了Kettle项目,原Kettle项目发起人Matt Casters加入了Pentaho团队,成为Pentaho套件数据集成架构师,从此,Kettle成为企业级数据集成及商业智能套件Pentaho的主要组成部分,Kettle亦重命名为Pentaho Data Integration(PDI)。Pentaho公司于2015年被Hitachi(日立) Data Systems收购,Hitachi Data Systems于2017年改名为Hitachi Vantara。
Pentaho Data Integration以Java开发,支持跨平台运行,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。Pentaho Data Integration分为商业版与开源版,开源版的截止2021年1月的累计下载量达836万,其中19%来自中国。在中国,一般人仍习惯把Pentaho Data Integration(PDI)的开源版称为Kettle。
2. kettle 与ETL
ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)
在各个企业中,对数据的处理几乎成为其数字化发展的必要流程,而数据的处理,无外乎抽取、统计分析、转换、装载,因此,各个企业目前都需要ETL工程师来完成数据的处理工作。
kettle是一个ETL工具,允许管理来自不同异构数据源的数据,并在基于图形化的工具中,完成对ETL的操作。
3. kettle的架构
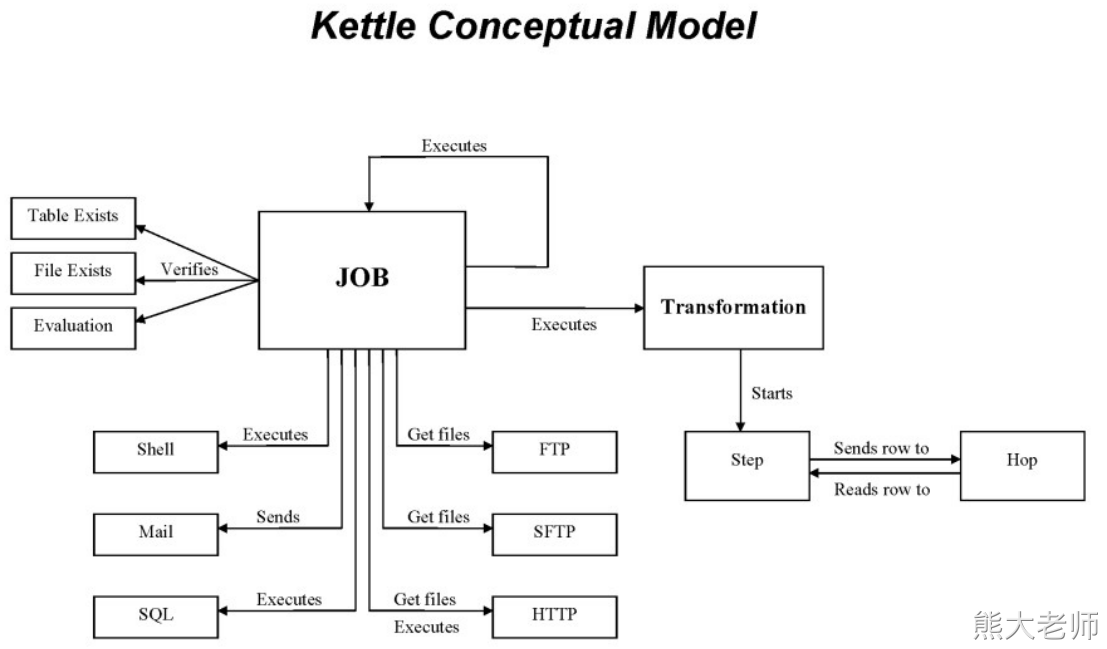
Transformation:转换
在大部分场景下,可以直接称之为“数据流”
它可以完成对数据的【输入】-->【处理】-->【输出】
一旦启动一个转换任务,则其中的所有组件会同时启动,并根据配置,逐条处理数据
Job:作业
作业可以称之为步骤流或者控制流
在作业中,可以挂载(调用)转换任务,也可以挂载(调用)job任务
作业中的各个组件,按照顺序执行,可以对执行的结果进行判断并处理分支
作业可以检测数据表、文件是否存在,执行Shell脚本,执行SQL脚本,获取数据,发送邮件等
核心组件:
组件 | 描述 |
spoon | 【勺子】是kettle的图形化工具,可以通过简单的拖拉拽方式完成kettle任务的设计、运行与调试,为kettle最常用的组件。 |
Pan | 【煎锅】Transformation执行器(命令行方式),Pan用于在终端执行Transformation,没有图形界面 |
Kitchen | 【厨房】Job执行器(命令行方式),Kitchen用于在终端执行Job,没有图形界面。 |
Carte | 嵌入式Web服务,用于远程执行Job或Transformation,Kettle通过Carte建立集群 |
4. kettle的特点
免费开源:基于java的免费开源的软件,对商业用户也没有限制,可以在任何的公司中使用。
容易配置:可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
兼容各种数据源:ETL工具集,它允许你管理来自不同数据库的数据。
简单开发:通过图形界面设计与开发任务,无需写代码实现。
二、kettle的安装
下载地址:https://community.hitachivantara.com/s/article/data-integration-kettle
目前最新的版本为9.3版本,在此我们使用9.1版本的kettle进行安装
安装要求:
安装所在的服务器或者Windows中,需要jdk1.8
在获取到压缩包之后,将压缩包解压至无中文路径下即可,注意,是整体路径中,任何一级目录中都不包含中文
解压后的目录结构如下:



三、kettle的初体验
需求:将一个csv文件中的数据内容输出到Excel文件中
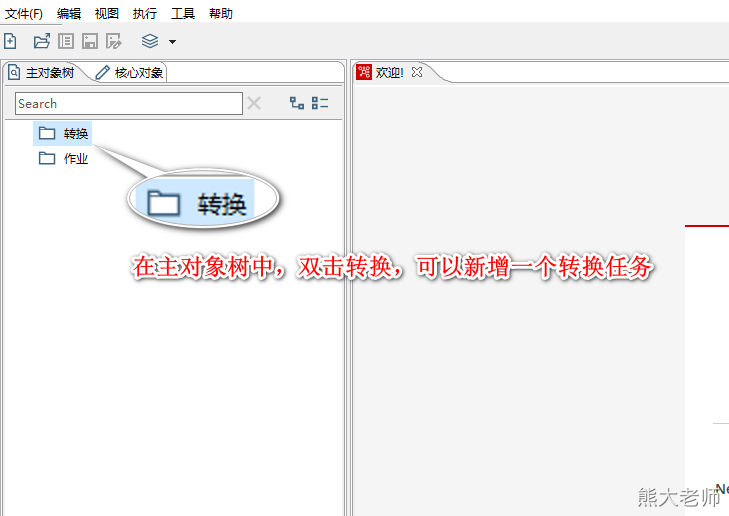
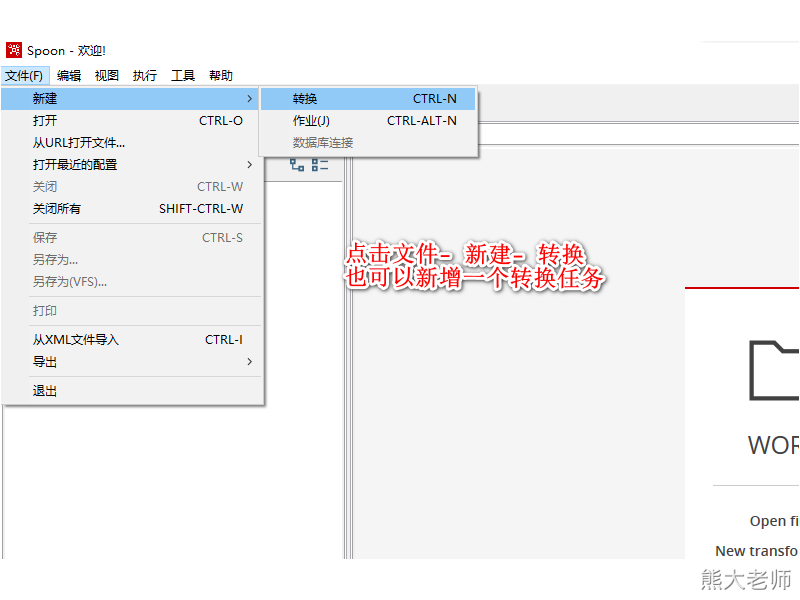
1. 新增转换任务
新增一个转换任务的方式:
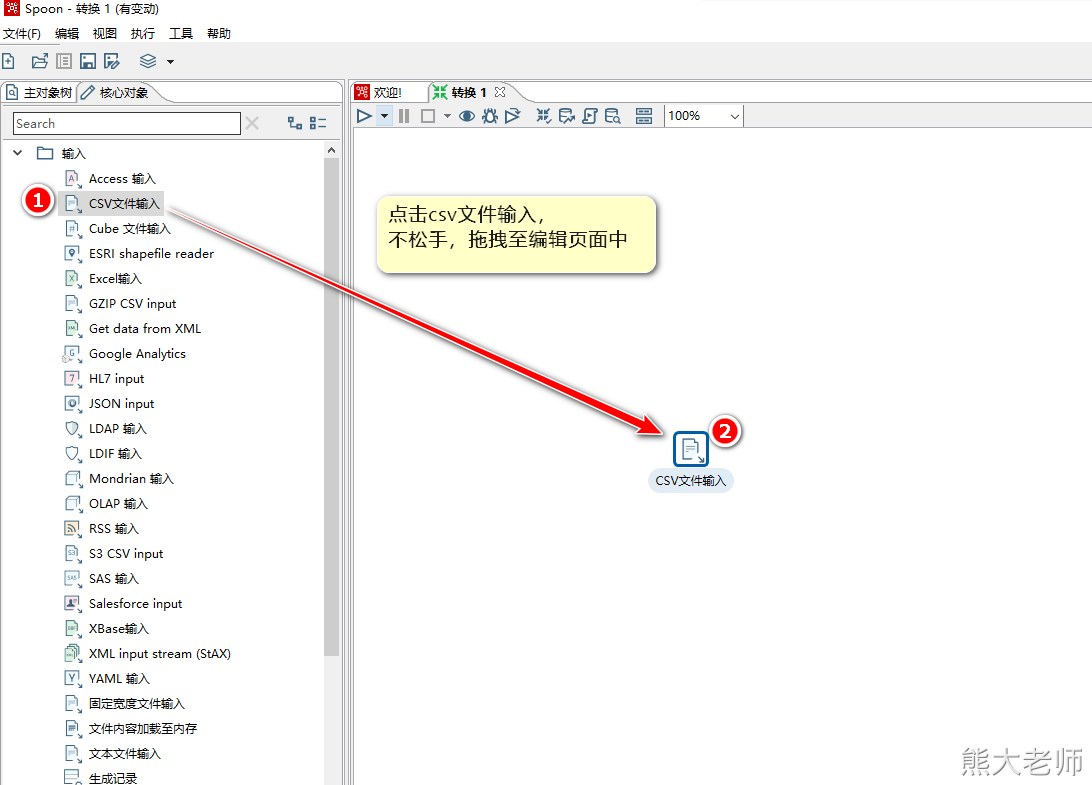
2. 配置csv输入组件(step)
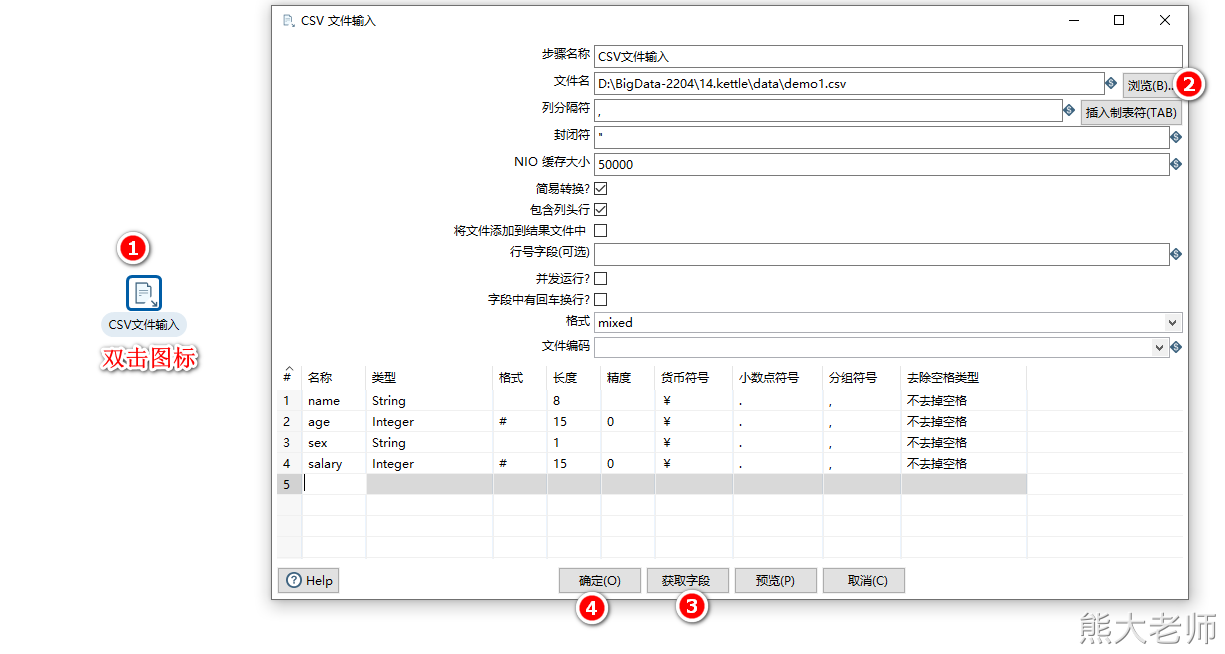
3. 配置Excel输出组件(step)
1)通过拖拽的方式将Excel输出放入编辑页面中
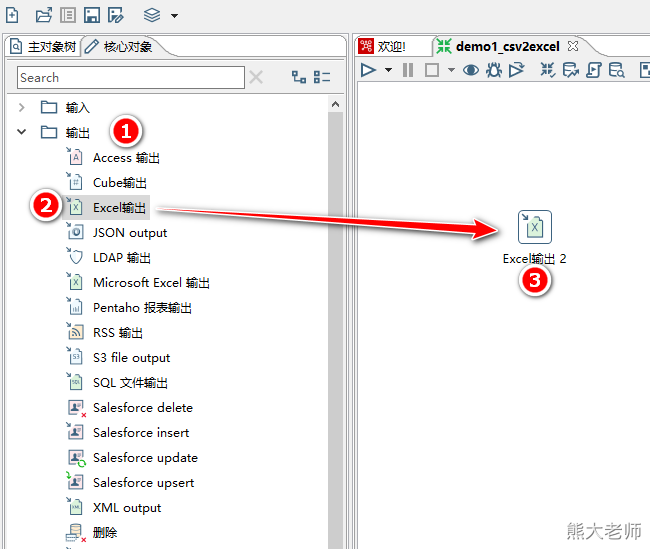
2)将输入组件与输出组件连接到一起:
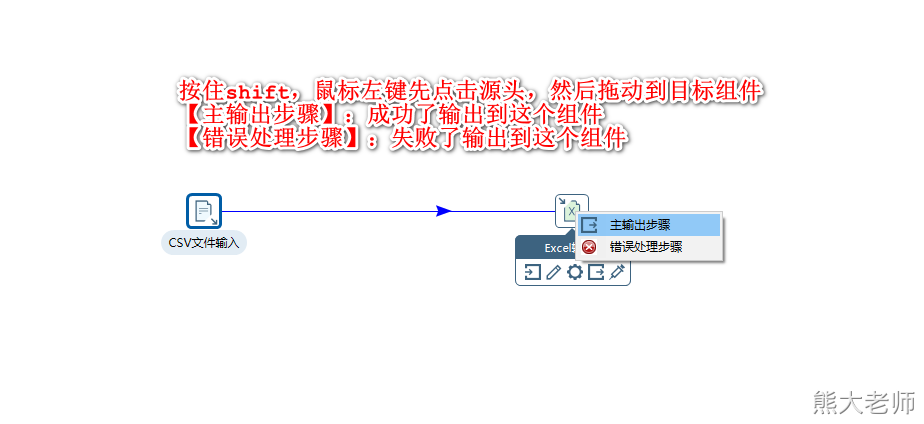
3)双击Excel输出组件,对内容进行配置
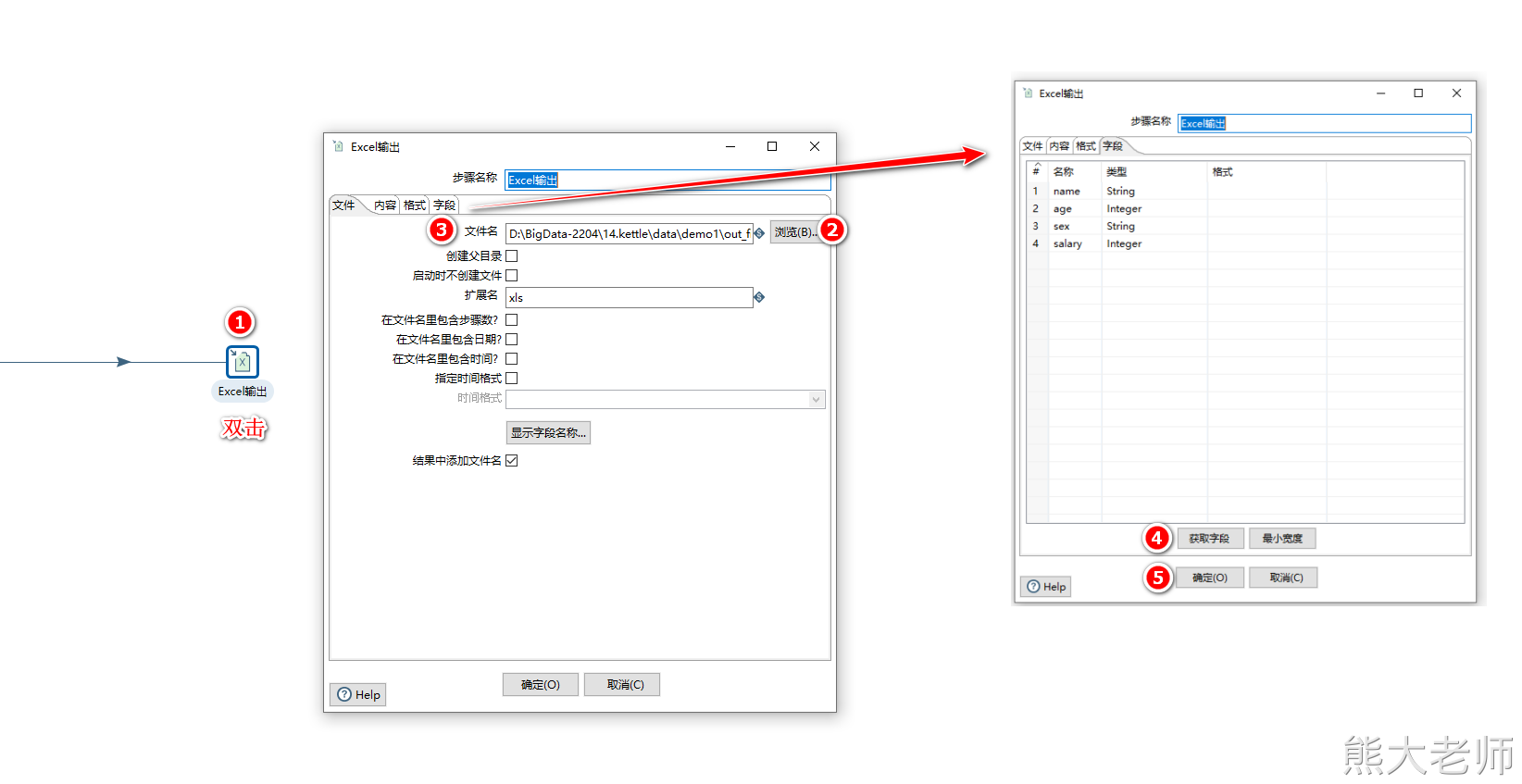
4. 创建作业(job)
1)双击【主对象树】中的作业或点击【文件】-【新建】-【作业】
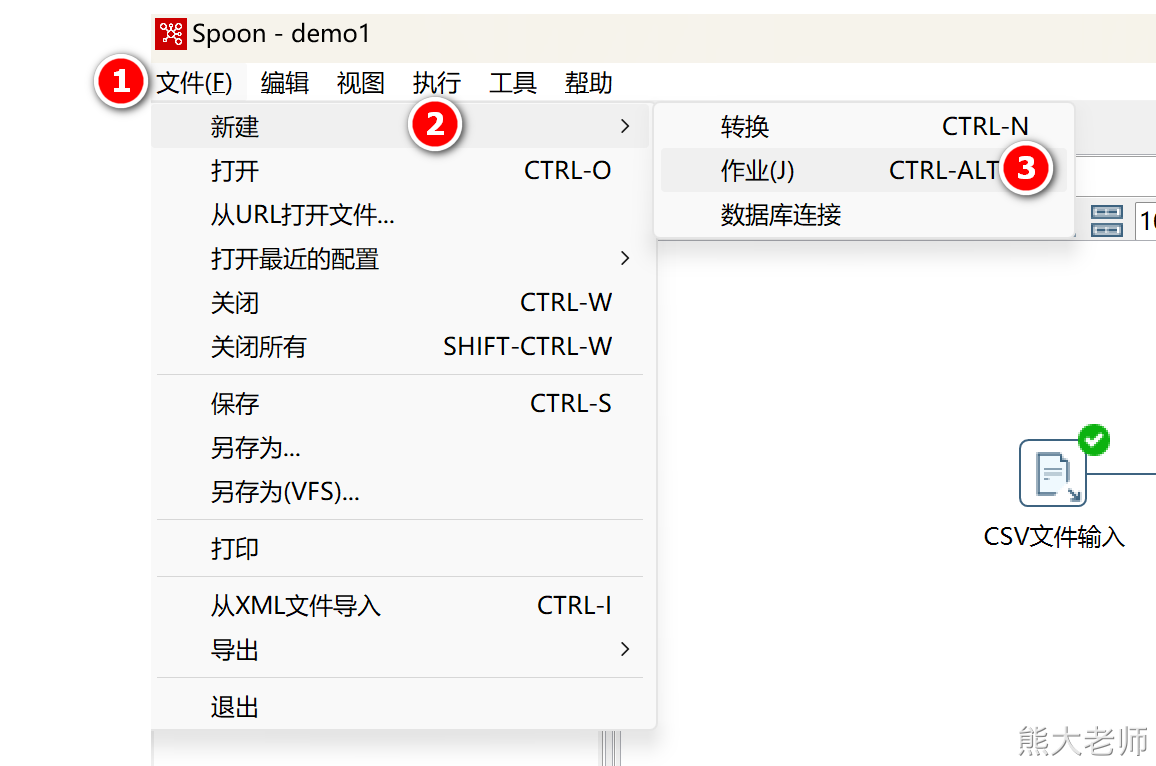
2)每个任务由一个start组件开始
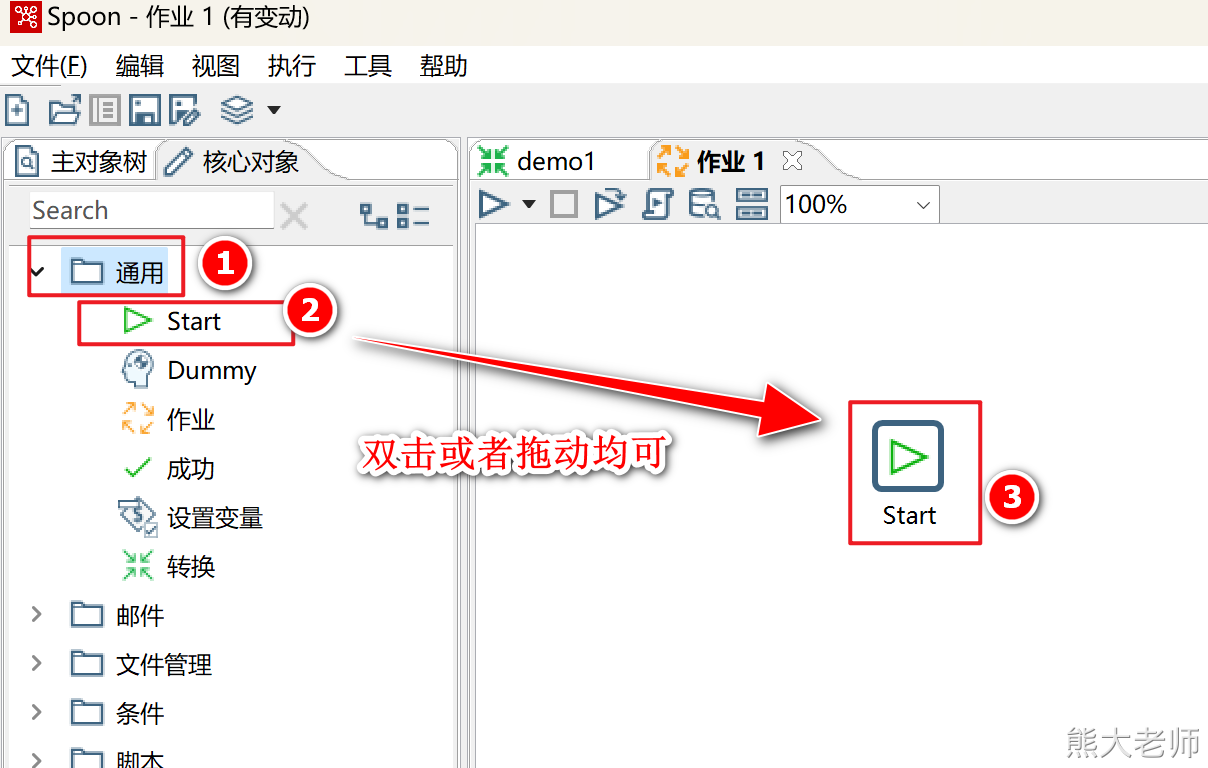
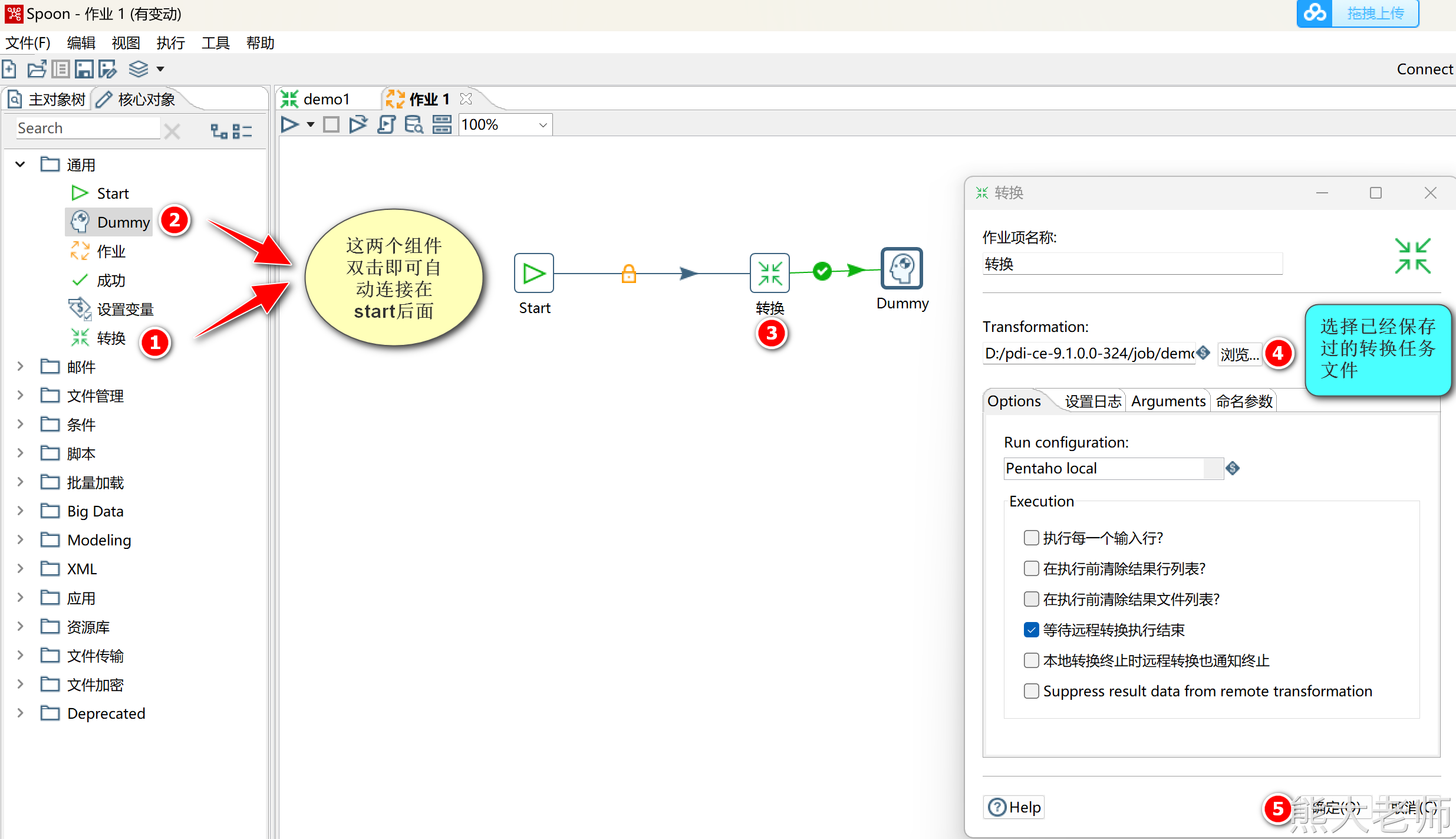
5. 在作业中挂载转换任务
配置转换任务与结束节点
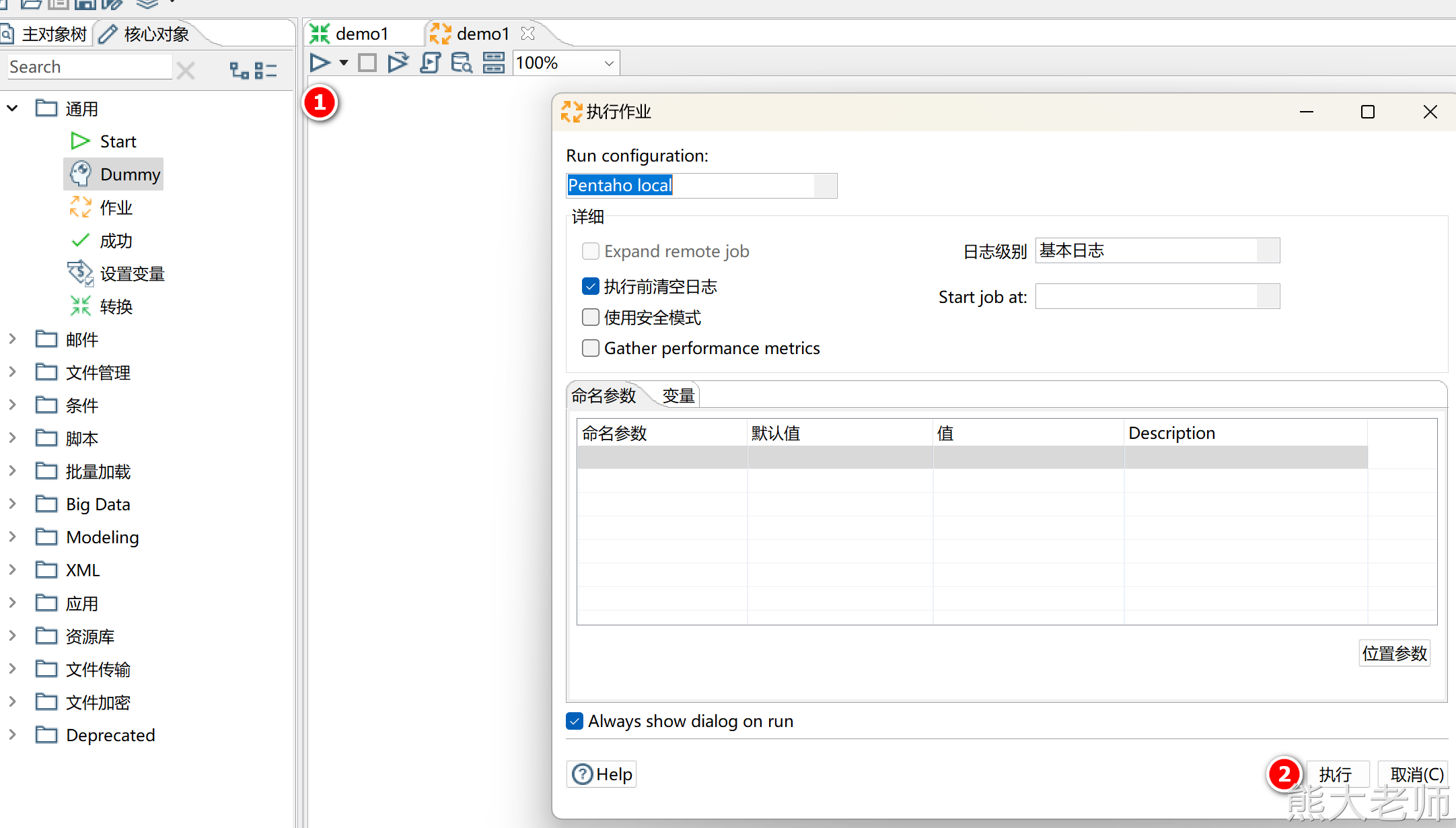
6. 测试运行
保存任务并执行
四、kettle名词解释
1. 转换
转换(transformation)是ETL解决方案中最主要的部分,它处理抽取、转换、加载各阶段各种对数据的操作。转换包含一个或多个“Step-步骤”,例如读取文件,过滤数据,数据加载等操作都是步骤。转换里的步骤通过“Hop-跳”来连接,跳定义了一个单向通道,允许数据从一个步骤向另一个步骤流动。此外,转换中的每个步骤还可以注释,目的主要是使转换文档化。
每个“Transformation-转换”对应的保存文件名称为“xx.ktr”
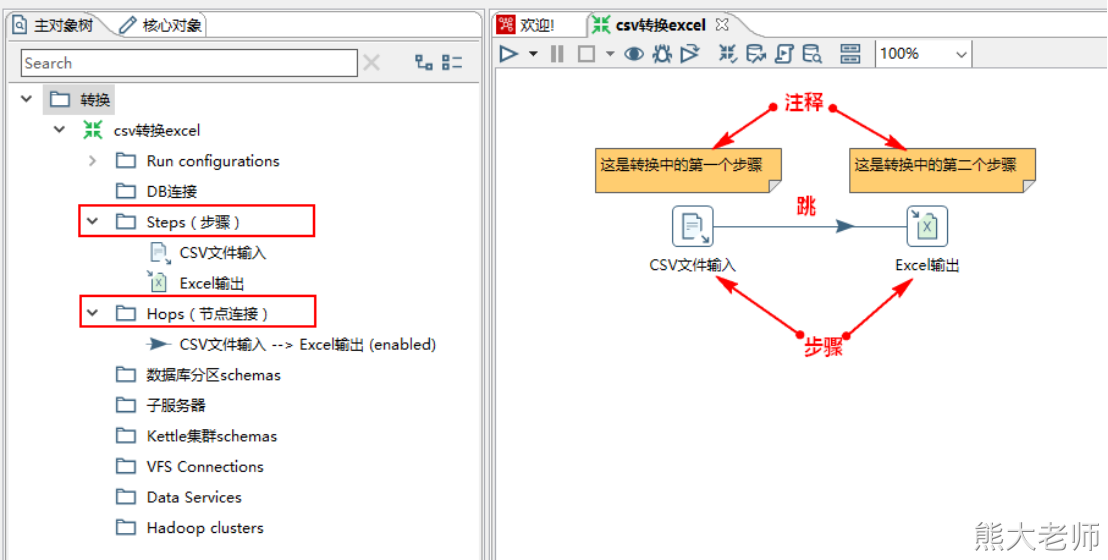
2. Step-步骤
Step是转换里的基本组成部分。
“CSV文件输入”和“Excel输出”显示了两个Step步骤。
每个Step都有唯一的一个名字,一个Step可以有多个输出跳,一个“步骤”的数据有多个输出跳时可以设置数据“分发”或者“复制”,“分发”是目标“步骤”轮流接收数据,“复制”是所有的记录被同时发送到所有的目标“步骤”。@
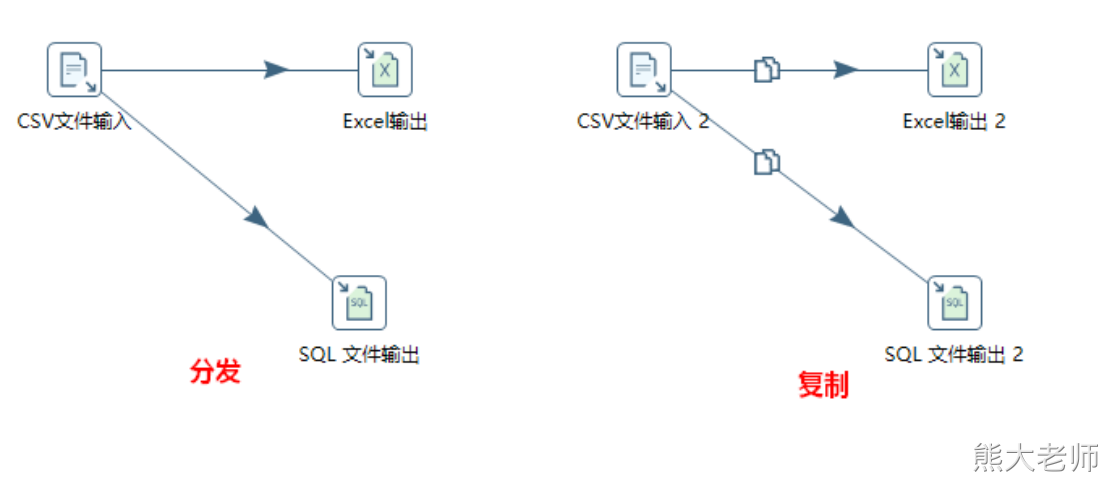
注意:分发会导致一份文件中的内容被发送到不通的文件中,输出到两个文件中的内容不同。
3. Hop-跳
“Hop-跳”就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路。在转换中“跳”不能循环,因为每个步骤都依赖前一个步骤获取字段值。所以转换任务是一个DAG(有向无环图)
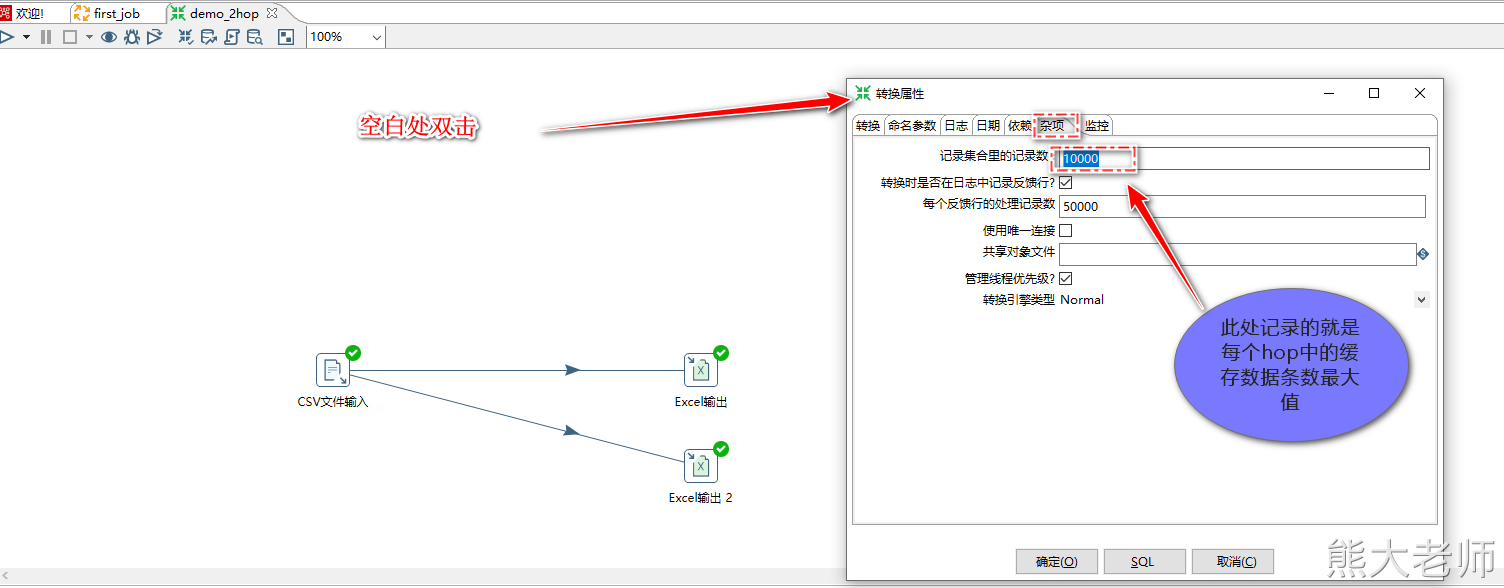
“Hop-跳”实际上是两个“Step-步骤”之间的记录行的缓存,缓存数据量可以在转换配置中设置(双击配置页面空白处),当缓存记录数满了,写数据的步骤停止写入,此时输出步骤不会停止,持续的读取缓存数据,直到缓存中有空间,写数据步骤继续运行。当缓存清空后,读取数据的步骤停止读取数据,直到缓存中又有数据。
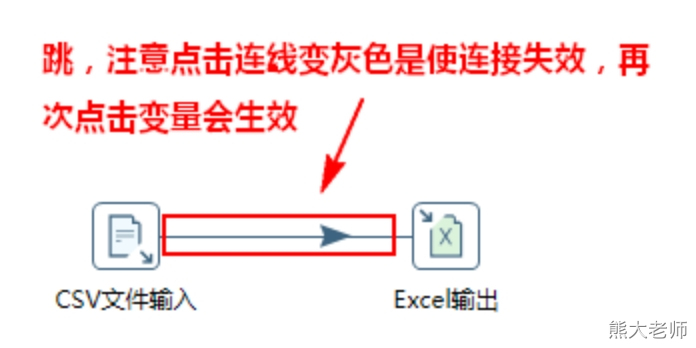
当单击“跳”时,连线变灰色,代表不使用,再次单击变蓝代表启用。
4. 并行(转换)
当“Transformation-转换”启动后,所有“Step-步骤”都同时启动,这些“Step-步骤”都是并发方式运行,各自从对应的输入跳中读取数据,并把处理过的数据写到输出跳,直到输入跳里不再有数据,就终止步骤的运行,当所有的步骤都终止了,整个转换就停止了。
“Transformation-转换”里的步骤几乎是同时启动的,所以不可能判断出哪个步骤是第一个启动的步骤。如果想要一个任务沿着指定的顺序执行,那么就要使用“Job-作业”。
5. 数据类型
数据以数据行的形式沿着步骤移动。一个数据行是零到多个字段的集合,字段包括下面几种数据类型:
String: 字符类型
Number: 双精度浮点数(3.14)
Integer: 带符号长整型
BigNumber: 任意精度数值(3.141592653)
Date: 带毫秒精度的日期时间值
Boolean: 取值为true和false的布尔值
Binary: 二进制字段可以包括图形、声音、视频及其他类型的二进制数据
6. Job-作业
大多数ETL项目都需要完成各种各样的操作,而且这些操作要按照一定顺序完成。因为转换以并行方式执行,就需要一个可以串行执行的作业来处理这些操作。
作业是步骤流,转换是数据流,这是作业和转换的最大区别。
作业的每个步骤必须等到前面的步骤都跑完了,后面的步骤才会执行
而转换会一次性把所有的控件全部先启动(一个控件对应启动一个线程)然后数据流会从第一个控件开始,一条记录,一条记录的流向最后的控件。
一个作业包括一个或多个作业项,这些作业项以某种顺序来执行。作业执行顺序由作业项之间的跳和每个作业项的执行结果来决定。 可以单机作业跳来改变作业跳的状态,有三种状态(锁-必须执行、对号-执行成功时、错号-执行失败时,这三种状态可以通过单击连线进行切换)。
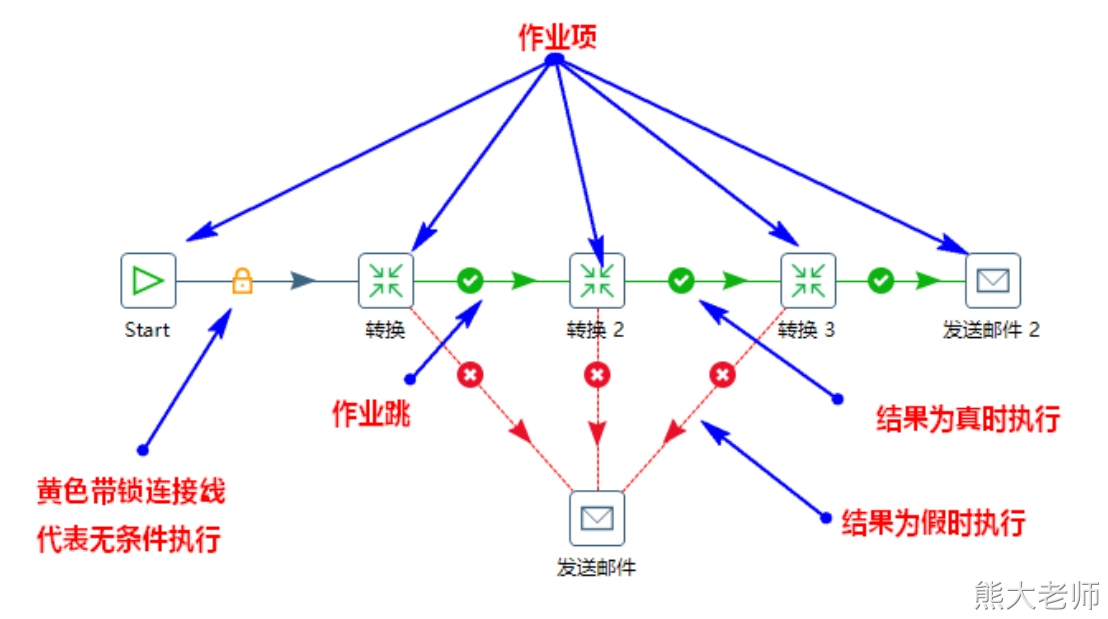
上图中的“Start”是“job-作业”的起点,一个作业只能定义一个“Start”。上图中每个“转换”就是作业的作业项,作业项是作业的基本构成部分。默认情况下作业中作业项都是以串行的方式制定,只是在特殊的情况下以并行方式执行。
当作业中有多条路径时,会采用回溯算法来执行作业项,如下图:
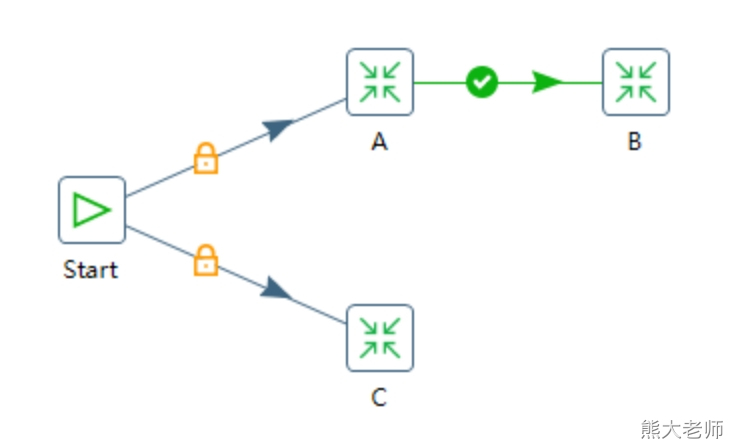
回溯算法就是:假设扫行到了图里的一条路径的某个节点时,要依次扫行这个节点的所有子路径,直到没有再可以执行的子路径,就返回该节点的上一节点,再反复这个过程。
上图中的三个作业的执行顺序如下:
首先“开始”作业项搜索所有下一个节点作业项,找到了“A”和“C”
执行“A”
搜索“A”后面的作业项,发现了“B”
执行“B”
搜索“B”后面的作业项,没有找到任何作业项
回到“A”,也没有发现其他作业项(需要被执行的作业项)
回到Start,发现另一个要执行的作业项“C”
执行“C”
搜索“C”后面的作业项,没有找到任何作业项
回到Start,没有找到任何作业项
作业结束。
以上执行过程就是Start->A->B->C,也有可能是Start->C->A->B。
作业除了以上串行执行外,还可以并行执行:
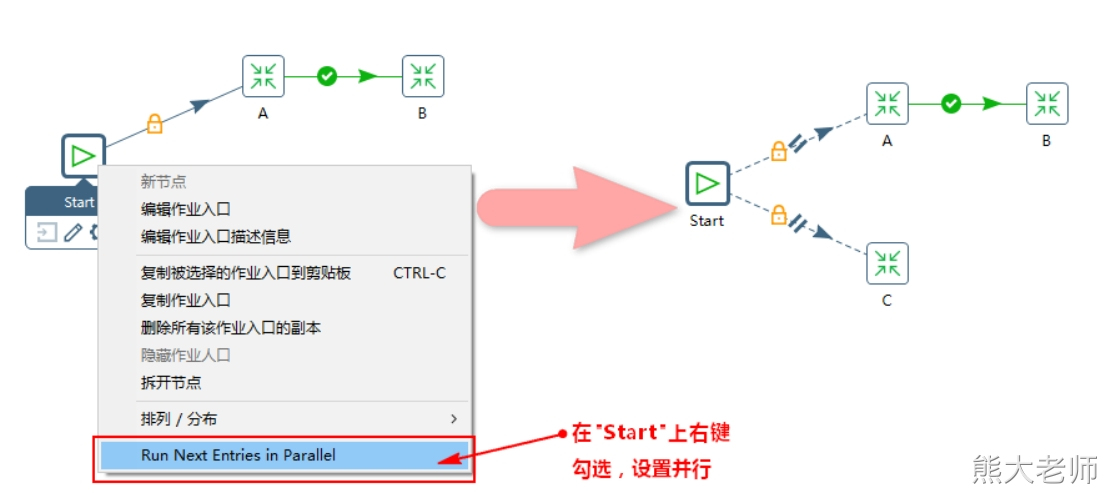
每个“Job-作业”对应的保存文件名称为“xx.kjb”。
五、转换核心对象
1. 输入
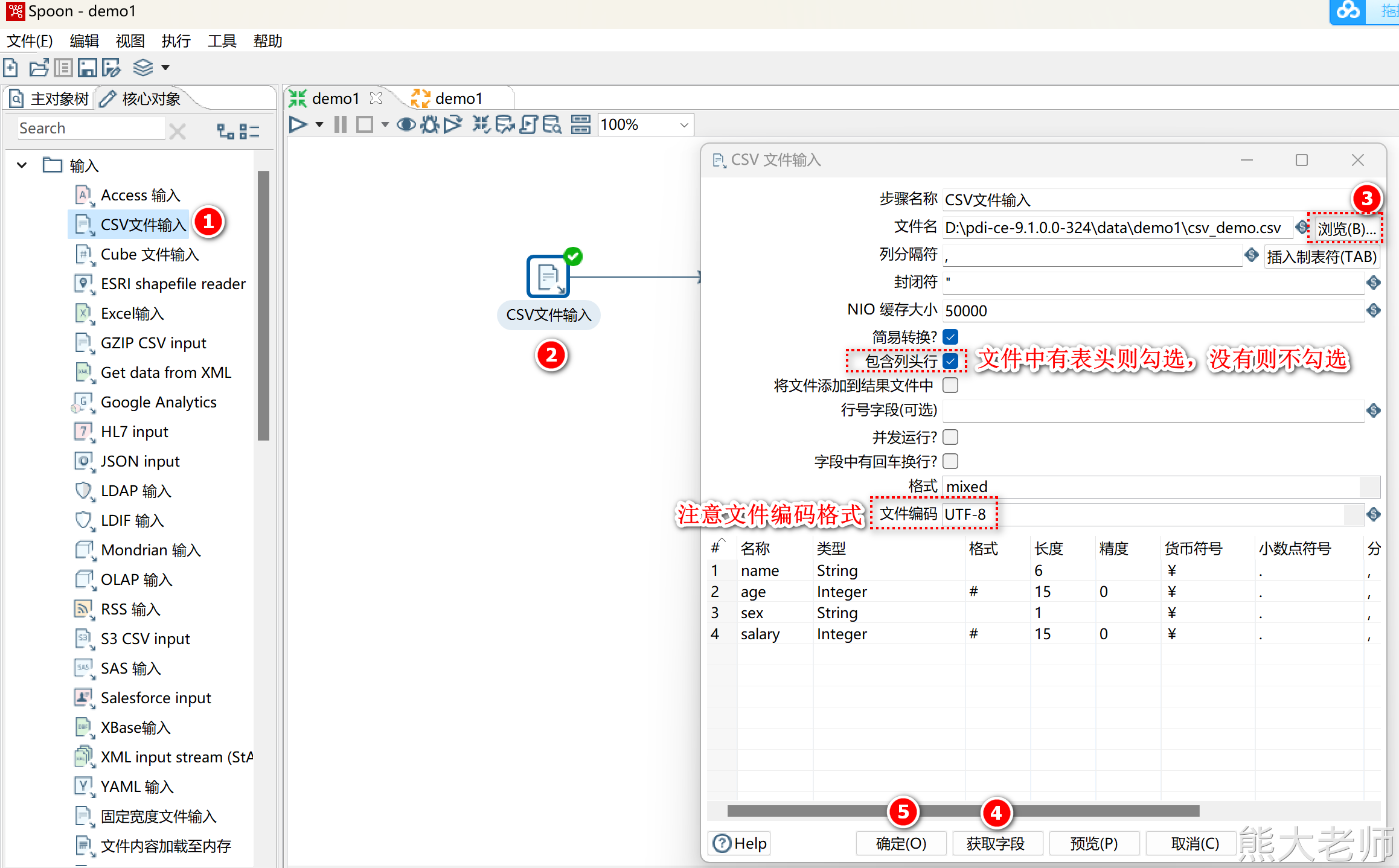
1) CSV文件输入
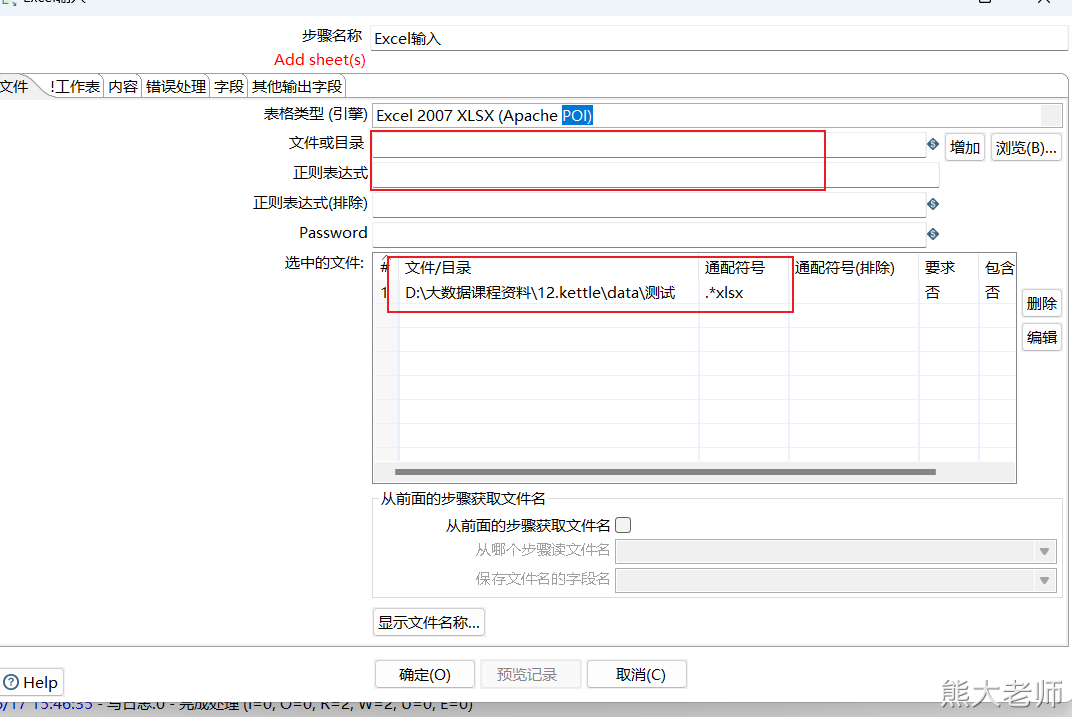
2) Excel输入
通过一个需求来熟悉一下Excel输入:
同时读取将两个Excel文件,并将其输出到指定的结果Excel文件中
创建Excel输入
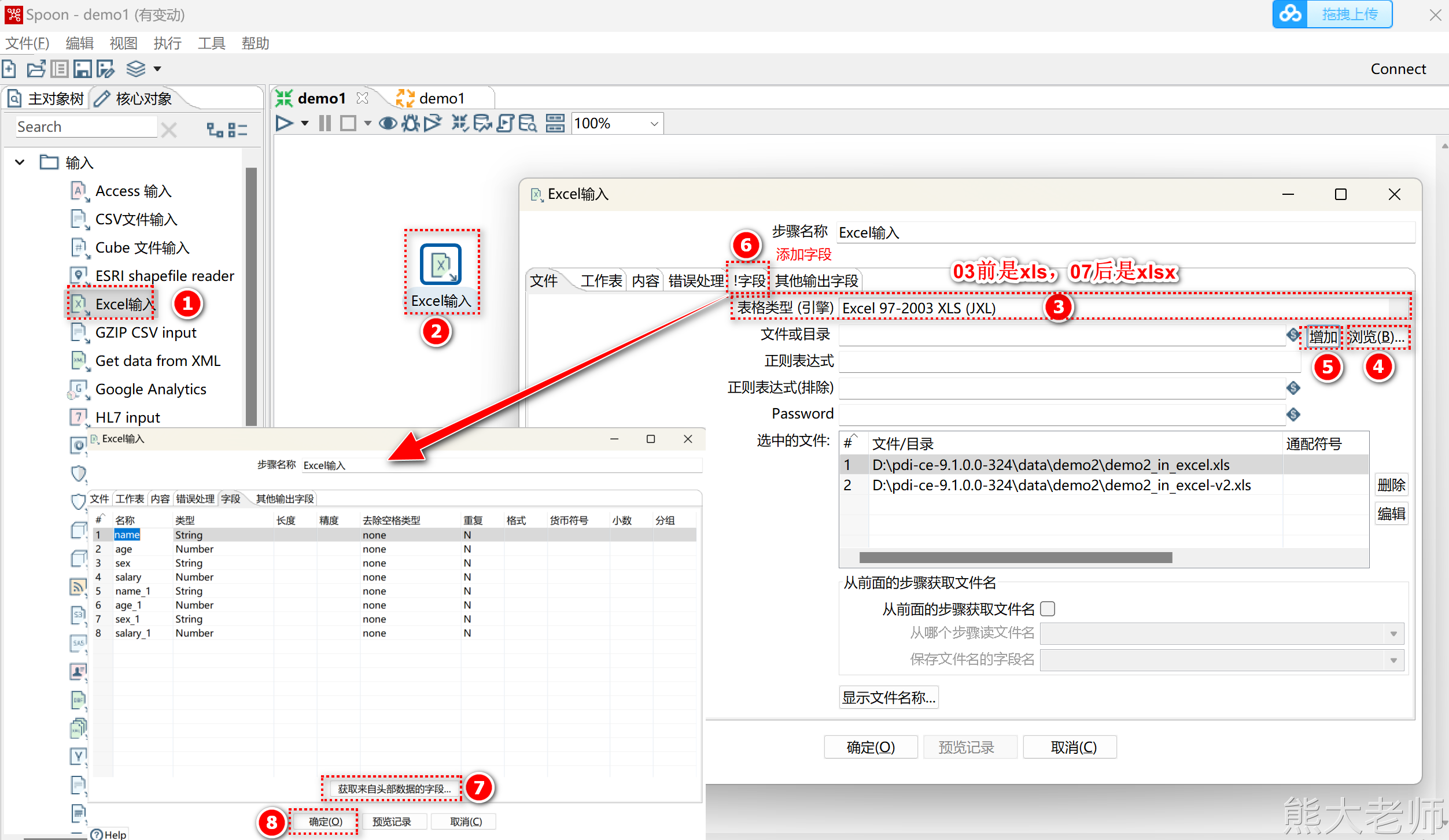
注意:kettle不支持读取使用Excel2007创建的Excel2003文件
创建Excel输出
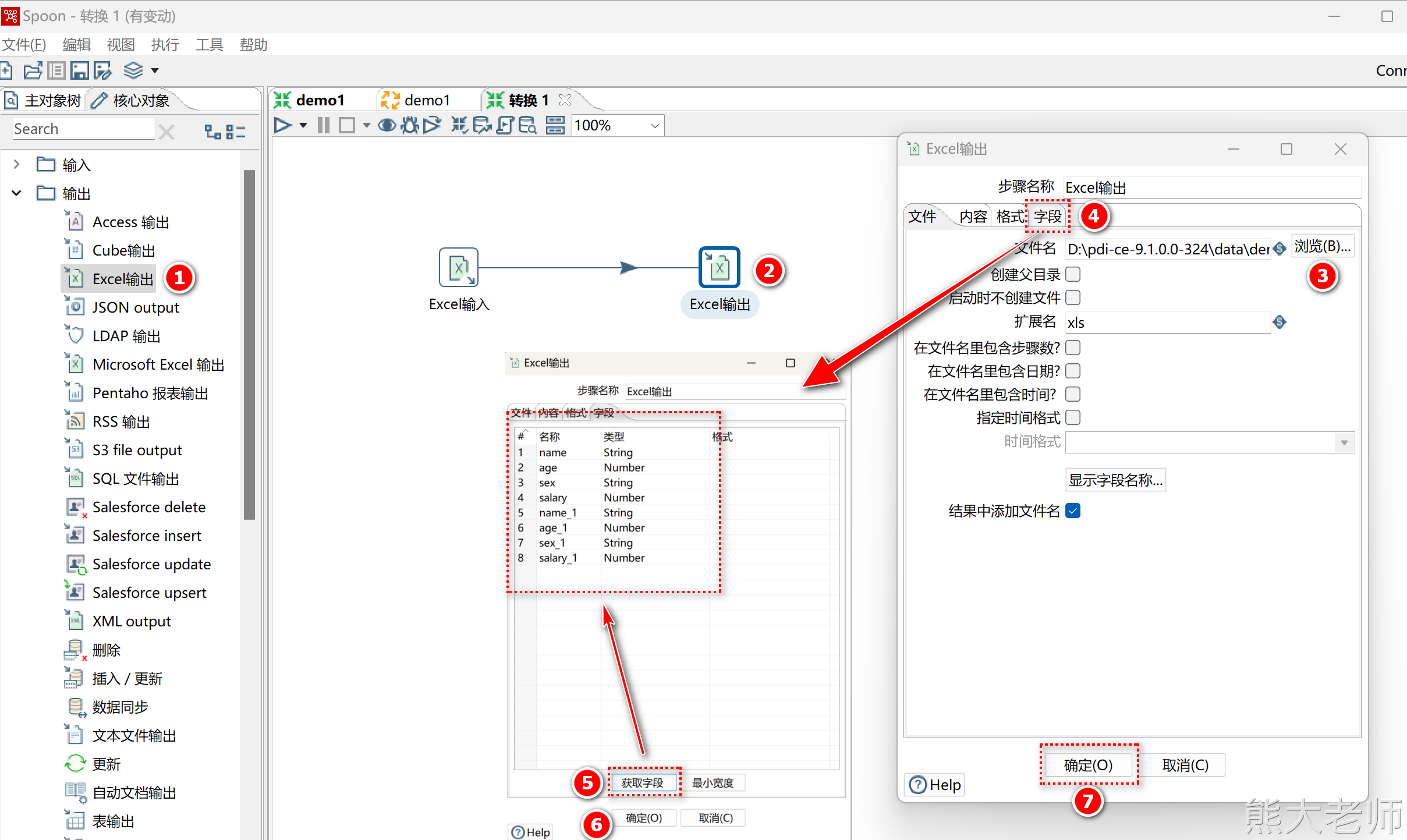
保存执行
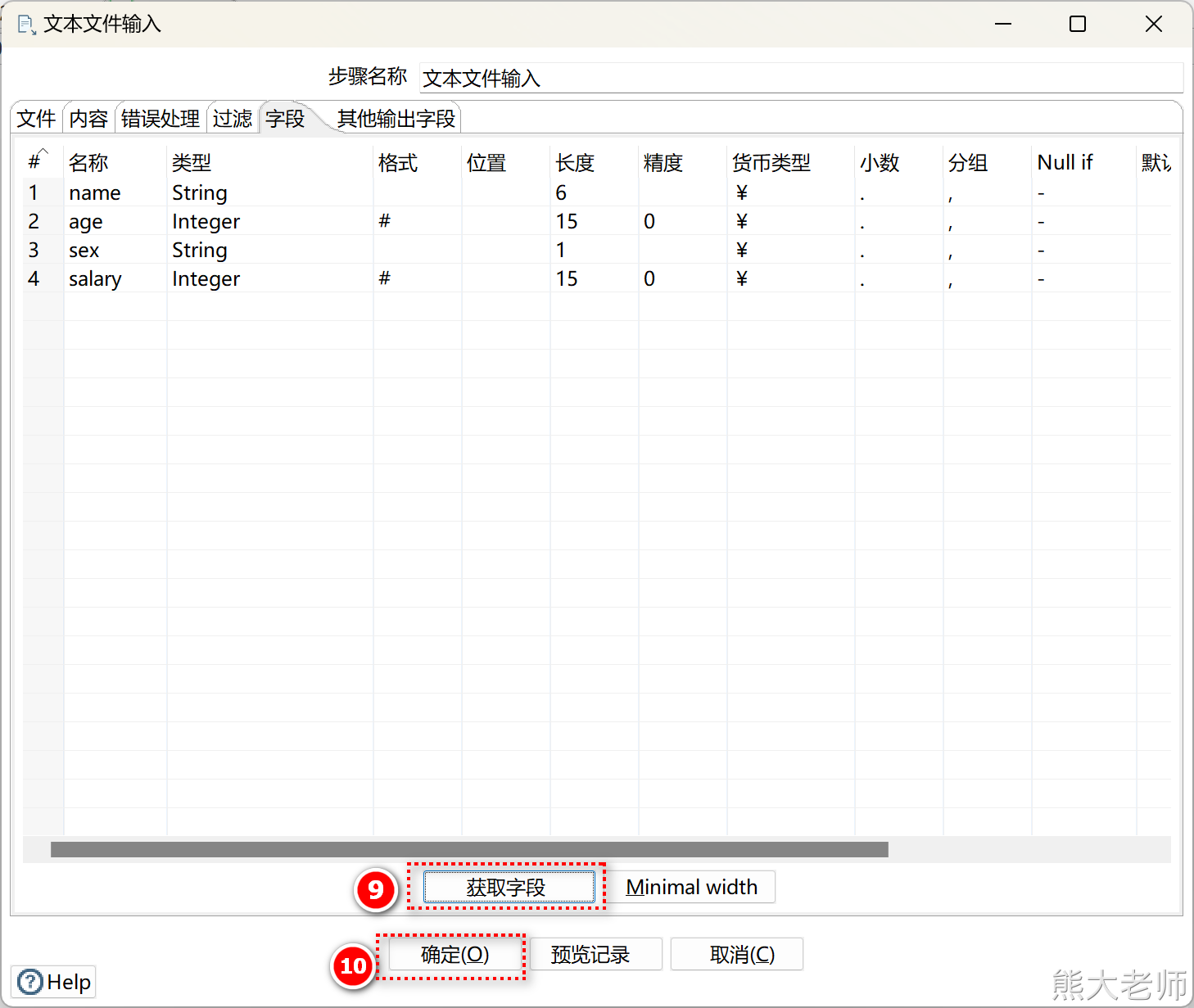
3) 文本文件输入
创建文本文件输入组件
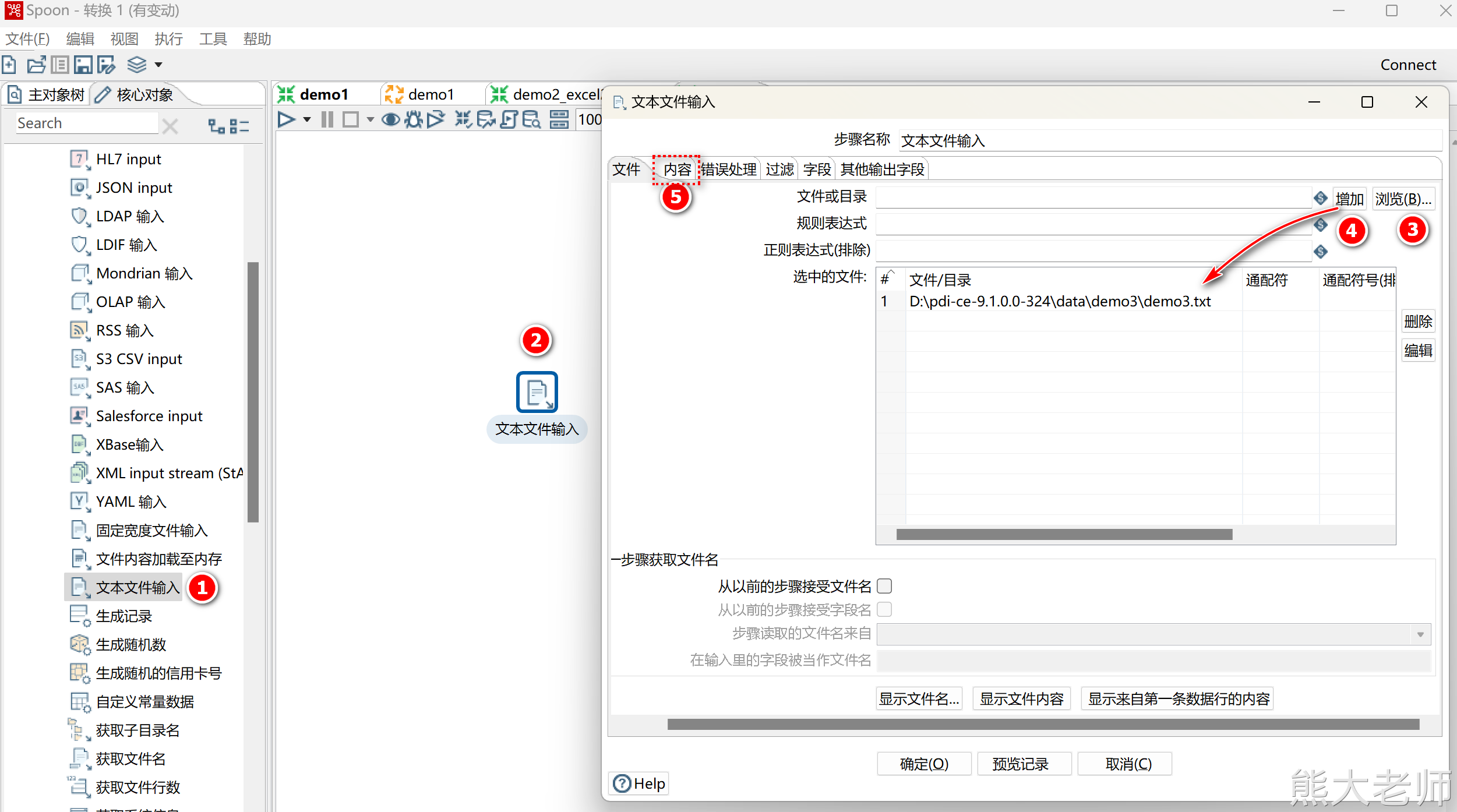
根据具体内容设置文件文件的配置
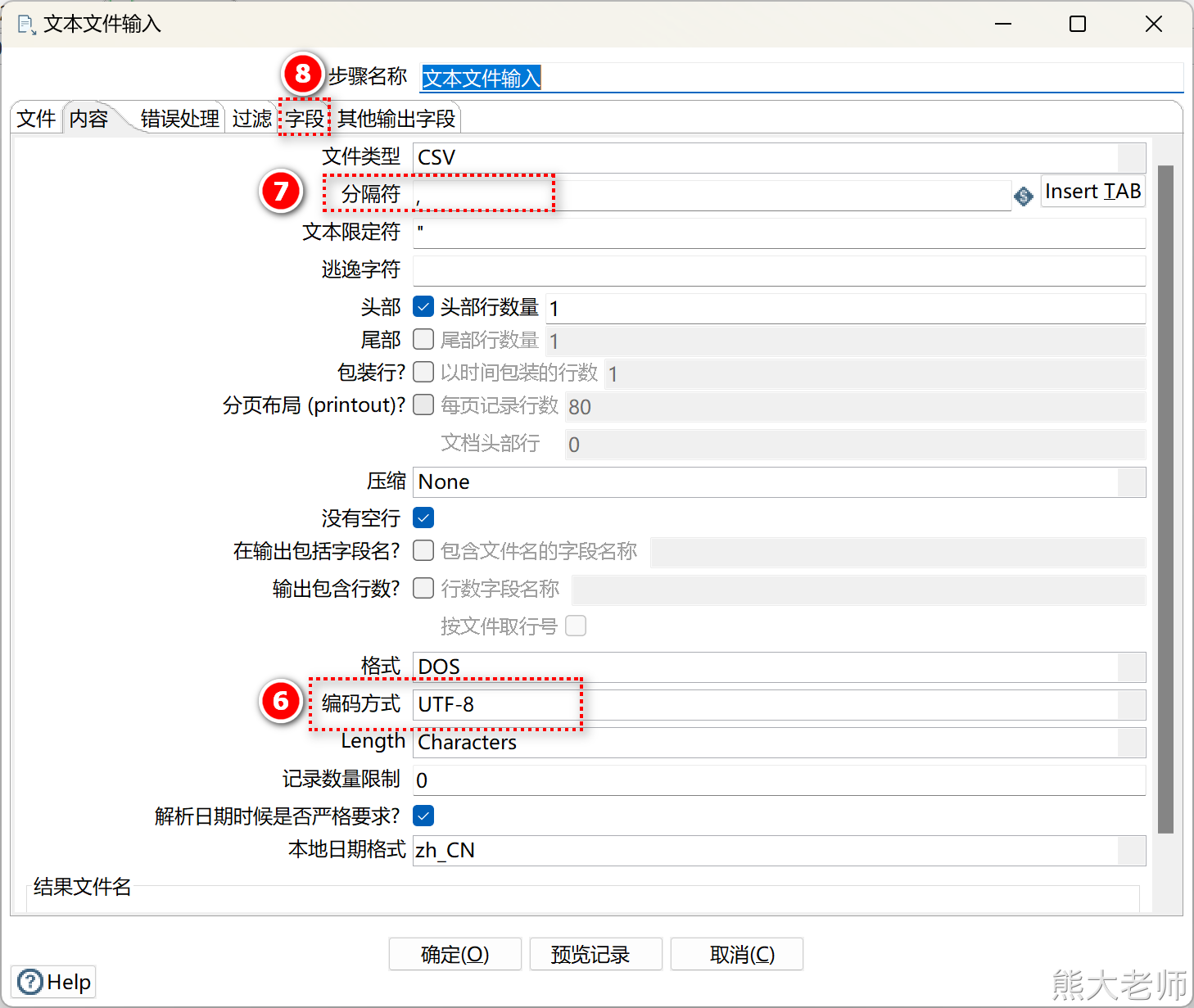
获取字段信息,完成组件配置
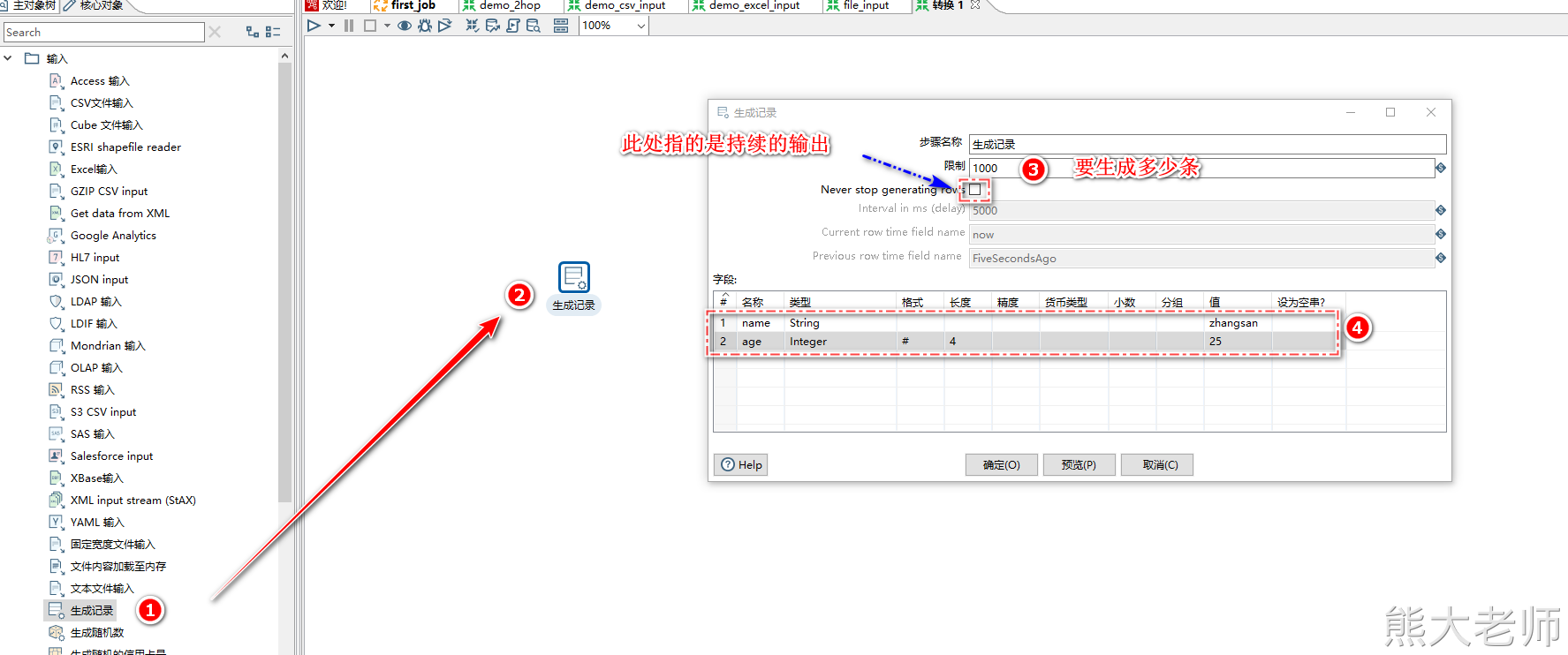
4) 生成记录
可以通过该步骤,完成测试数据的生成
补充:如何将任务放入到linux中执行
首先将kettle的压缩包放入linux中,并通过unzip进行解压,如果没有指令可以通过yum install unzip 进行安装
解压指令:unzip 包名 -d /opt/installs
将配置好的任务传入linux中,建议在kettle的目录中新建一个job目录,将其放入
vim 配置文件.ktr 将其中的输出与输入目录改为linux中的具体目录
在kettle的主目录中,执行:./pan.sh -file=./job/generate_input.ktr
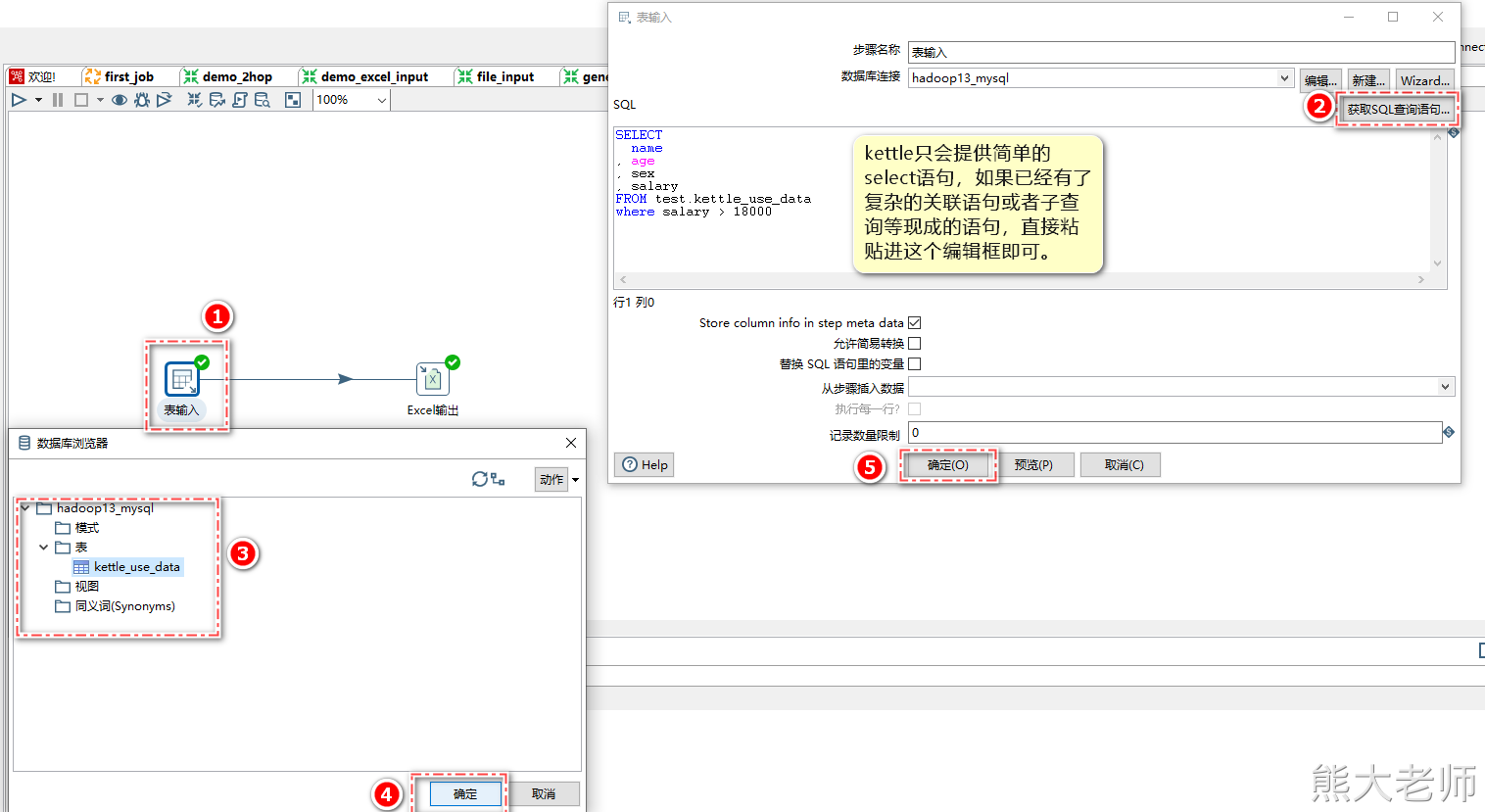
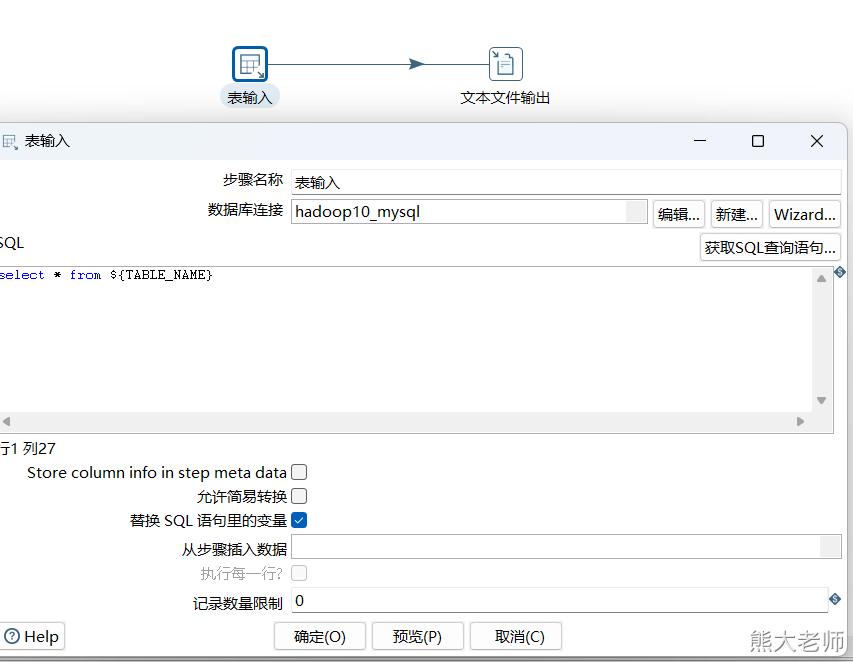
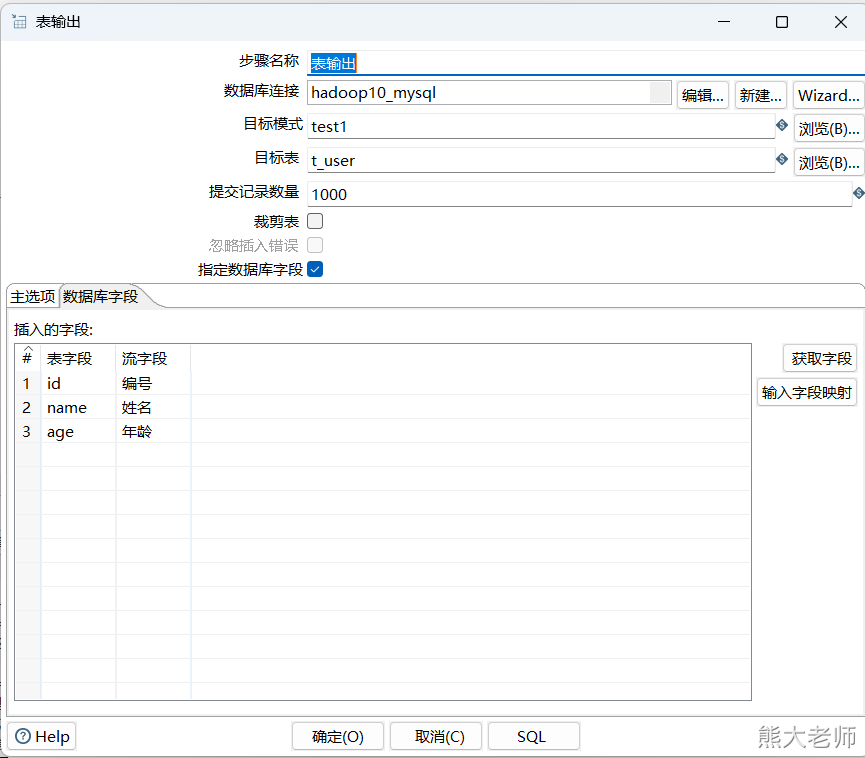
5) 表输入
Kettle支持抽取数据库表中的数据,以MySQL为例, 需要将mysql的驱动包放入Kettle解压目录“...\data-integration\lib”下,这里放入之后,需要重新启动Kettle。
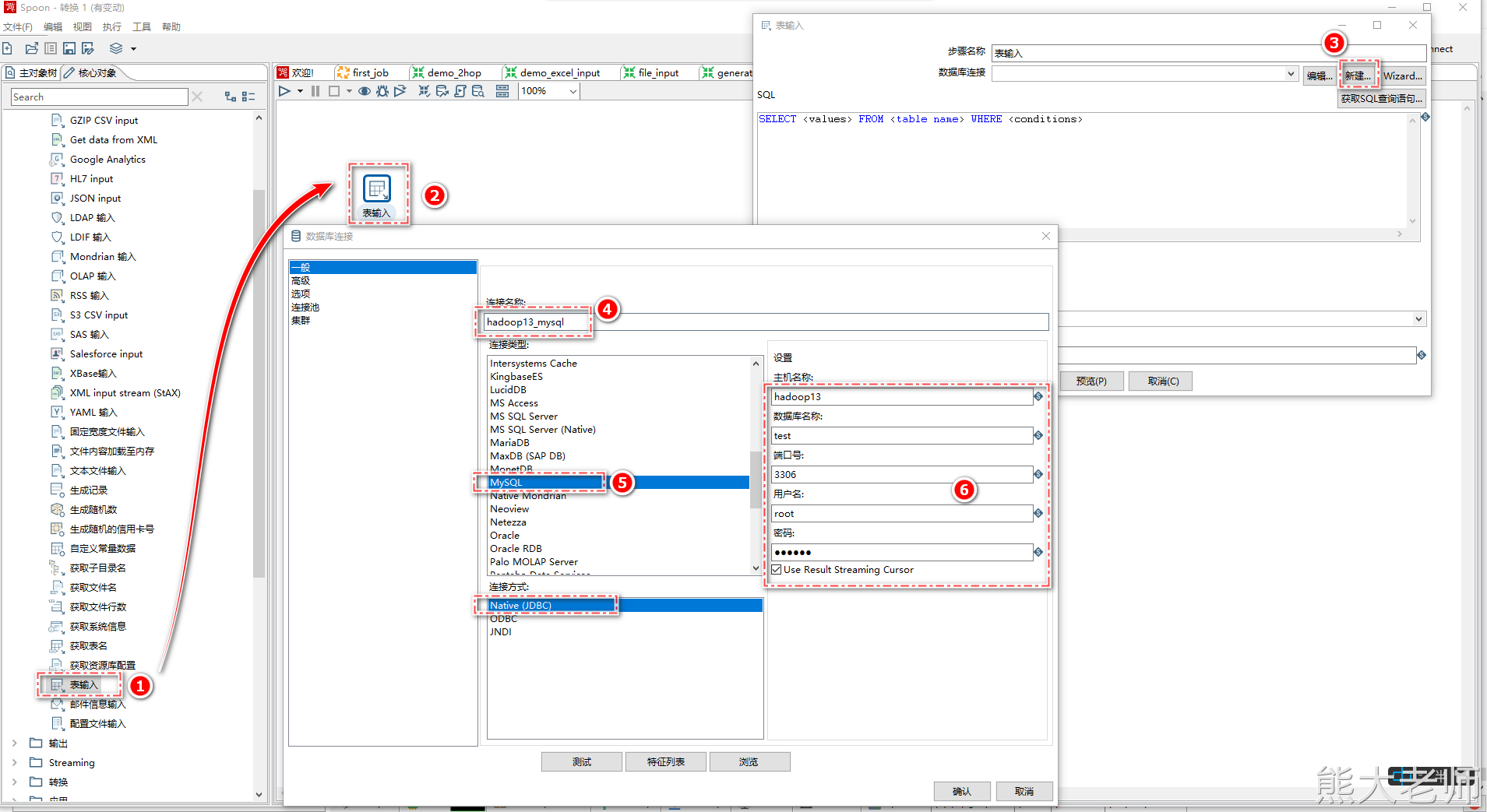
在新建的一个【转换】配置了mysql数据库的连接,但在其他的转换任务中,无法直接使用,需要将此数据库连接共享才可以完成所有转换任务的共同使用。
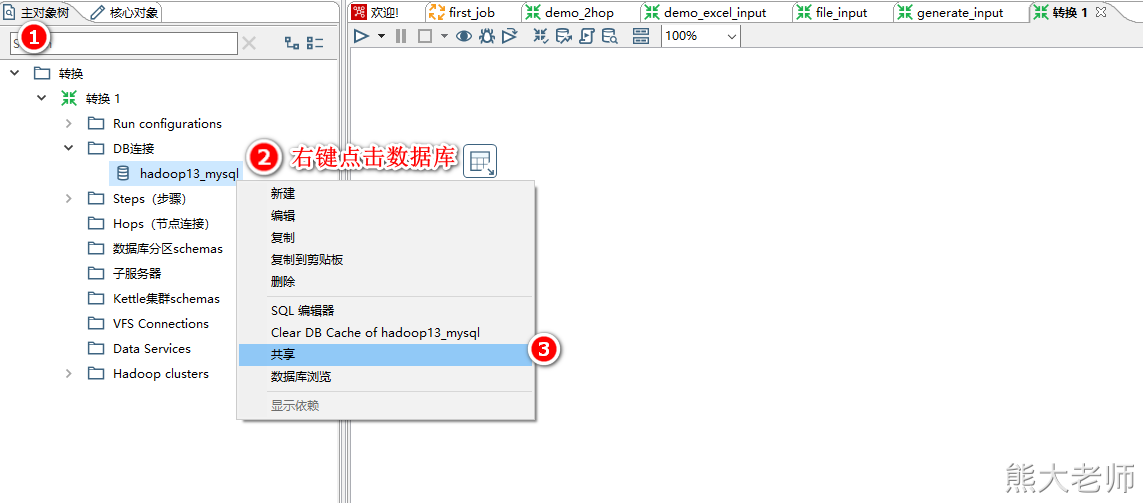
配置表输入step
2. 输出
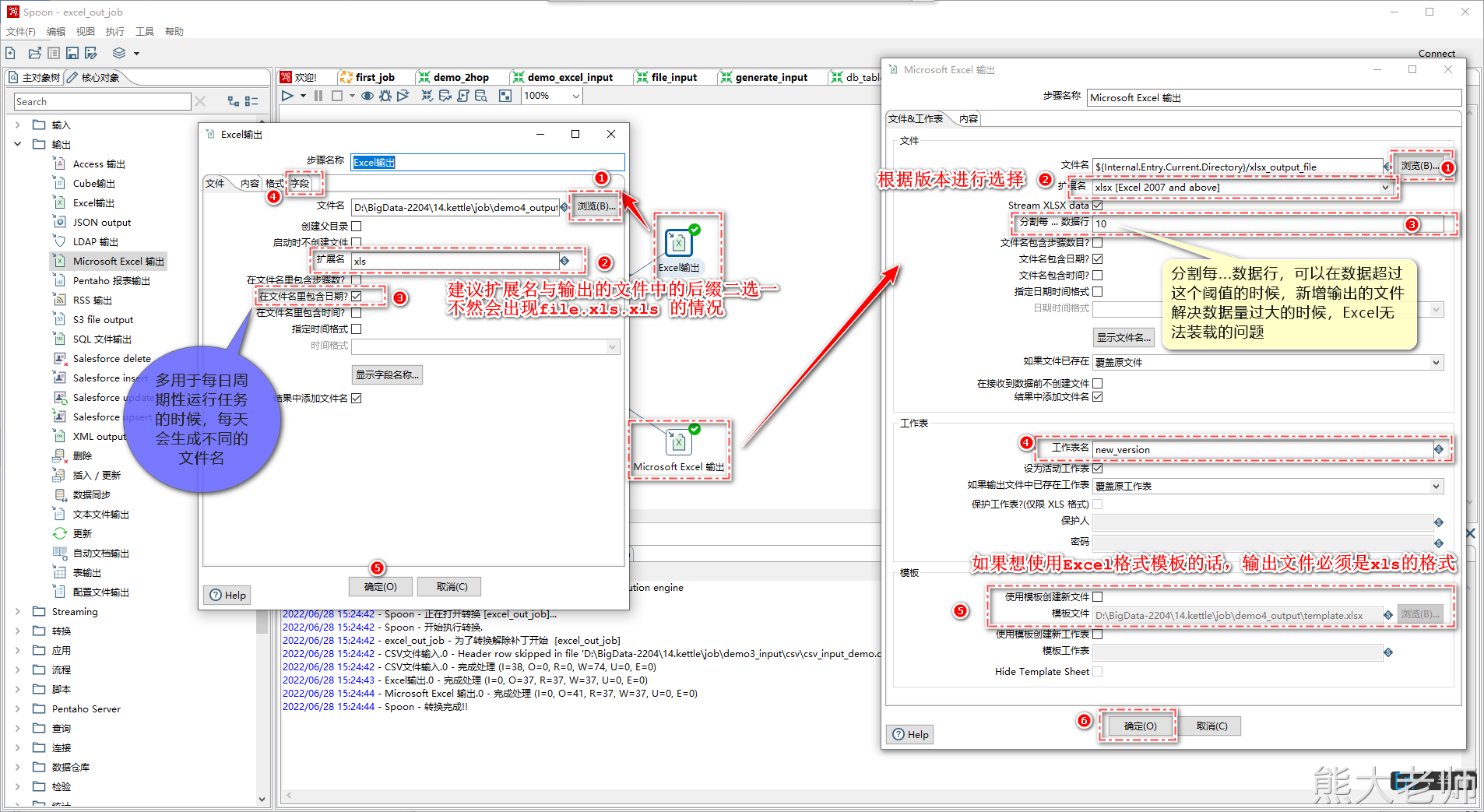
1) Excel输出/MicrosoftExcel输出
Excel输出”和“MicrosoftExcel输出”都是Excel输出,不同的是“Excel输出”写出支持“xls”格式,“MicrosoftExcel输出”支持“xls”和“xlsx”格式。
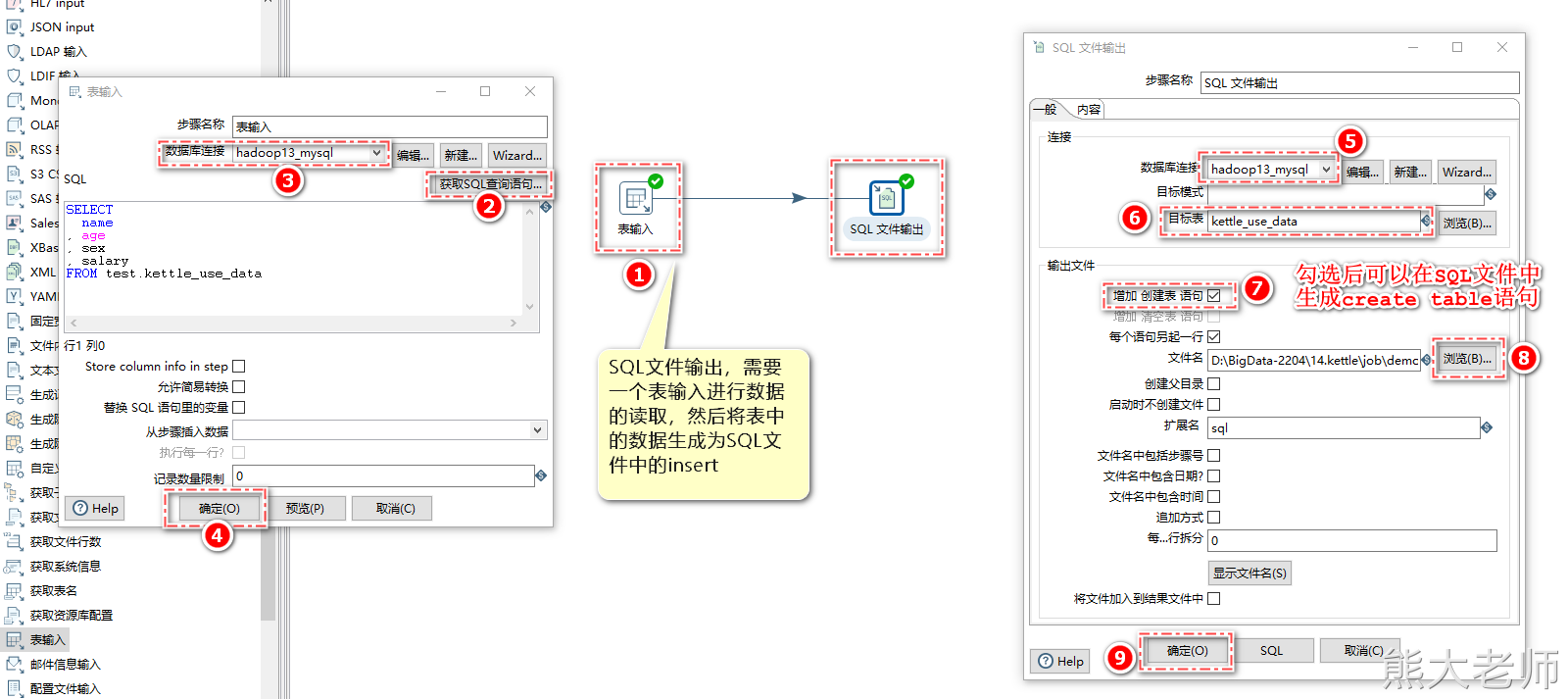
2) SQL文件输出
在某些场景下,需要对数据库中的某个表进行备份或者迁移的动作,可以使用【SQL文件输出】步骤进行数据的处理。
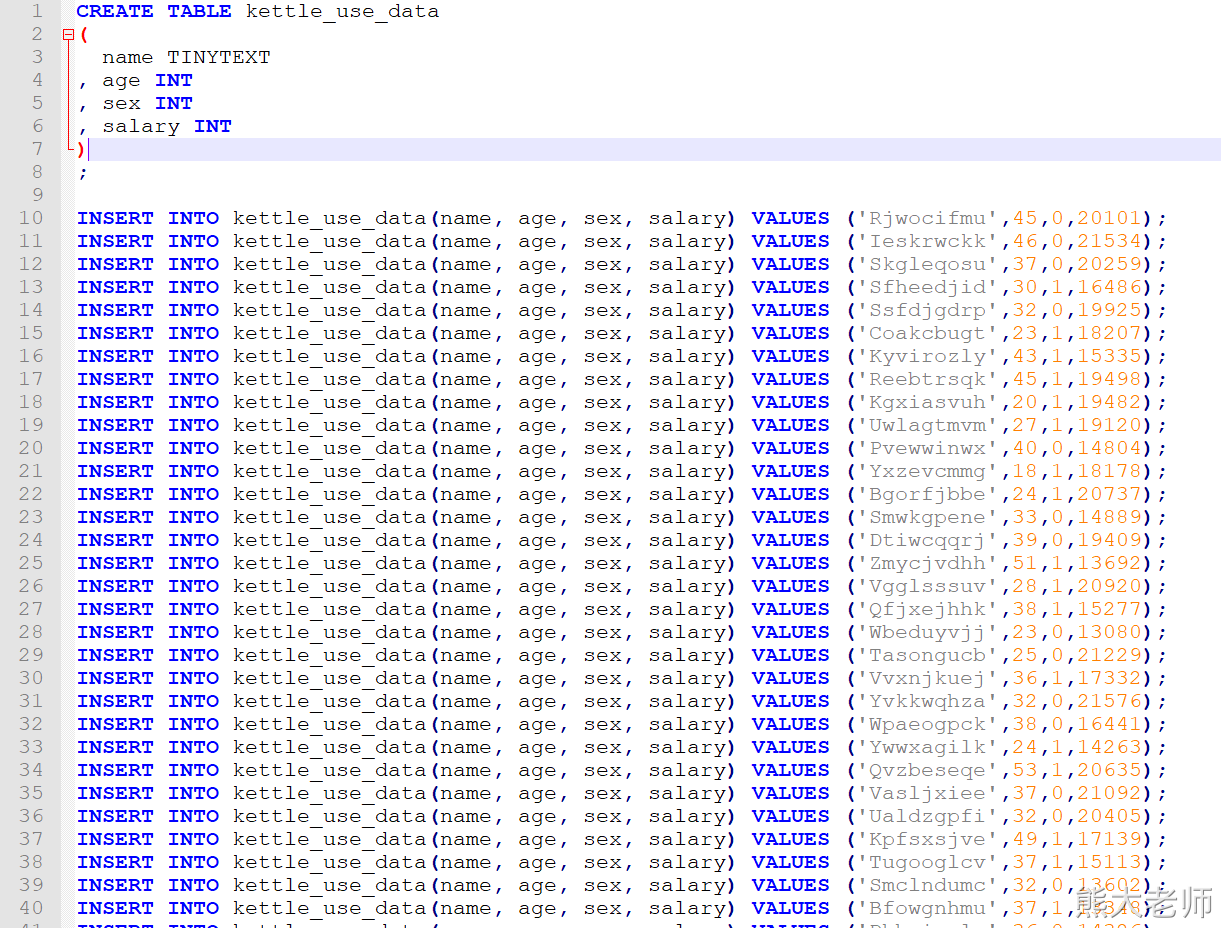
生成结果示例:
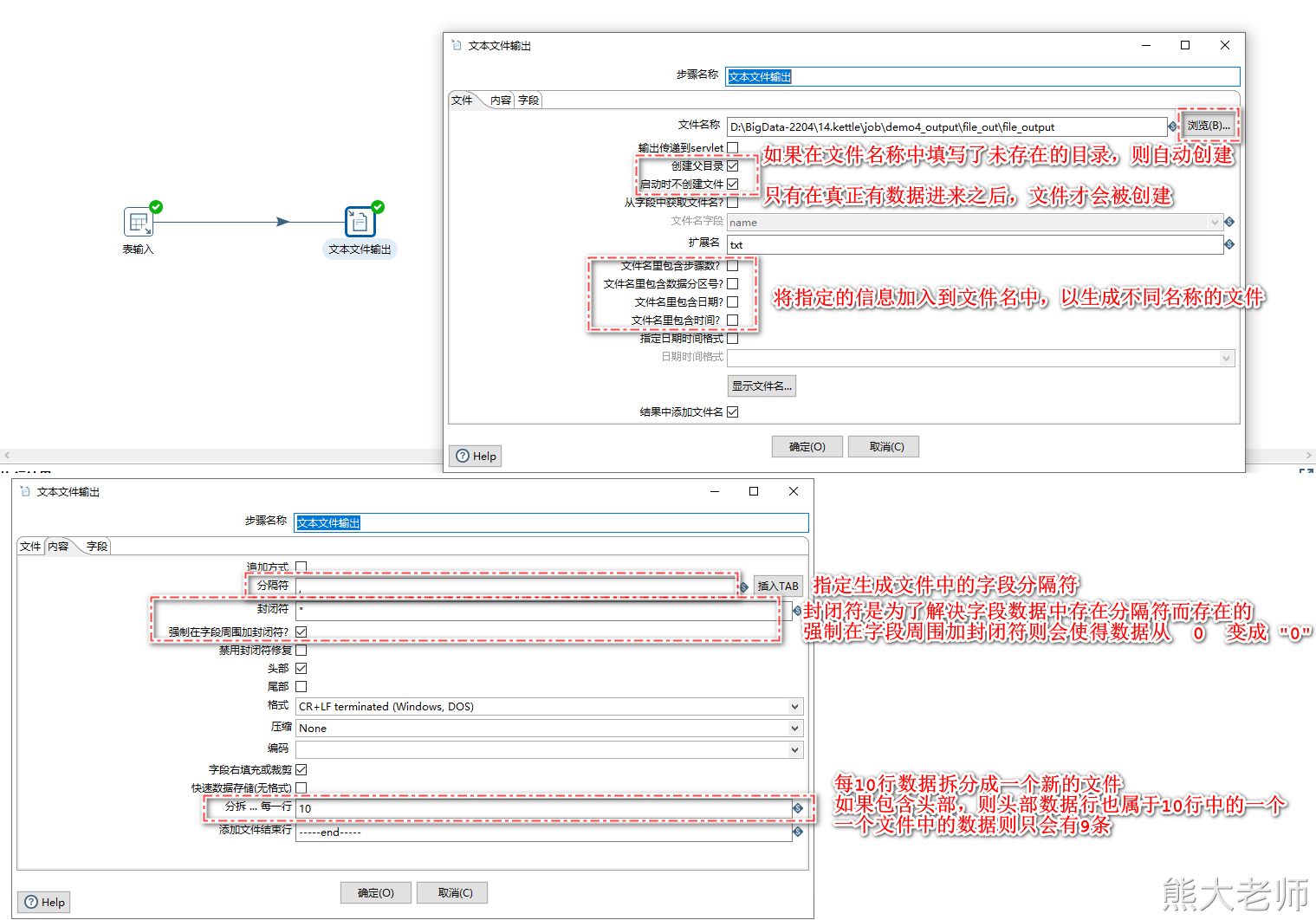
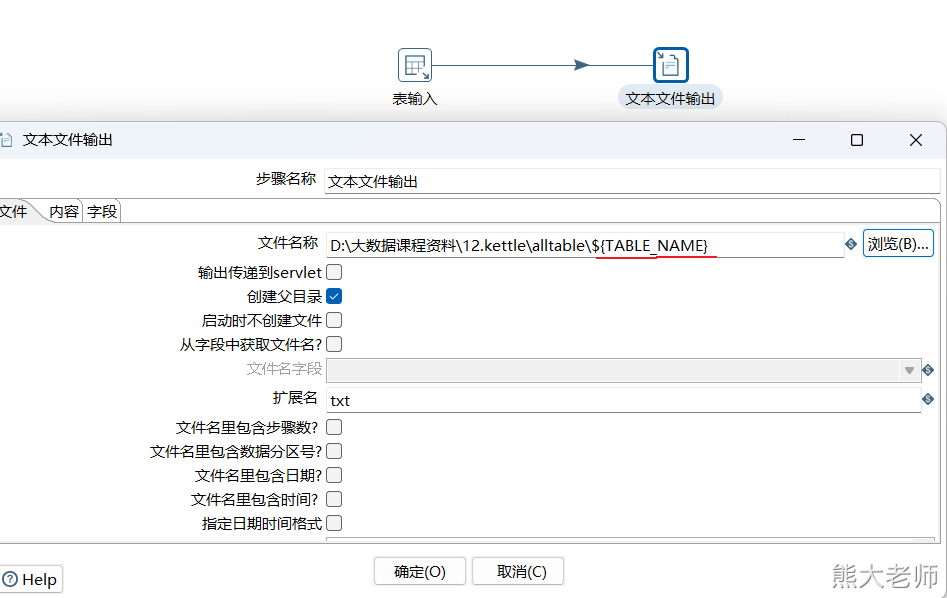
3) 文本文件输出
文本文件输出可以将各种数据源中的数据生成为文本文件,大多数的使用场景是将数据放入linux中,供hive等数据库数据分析使用。
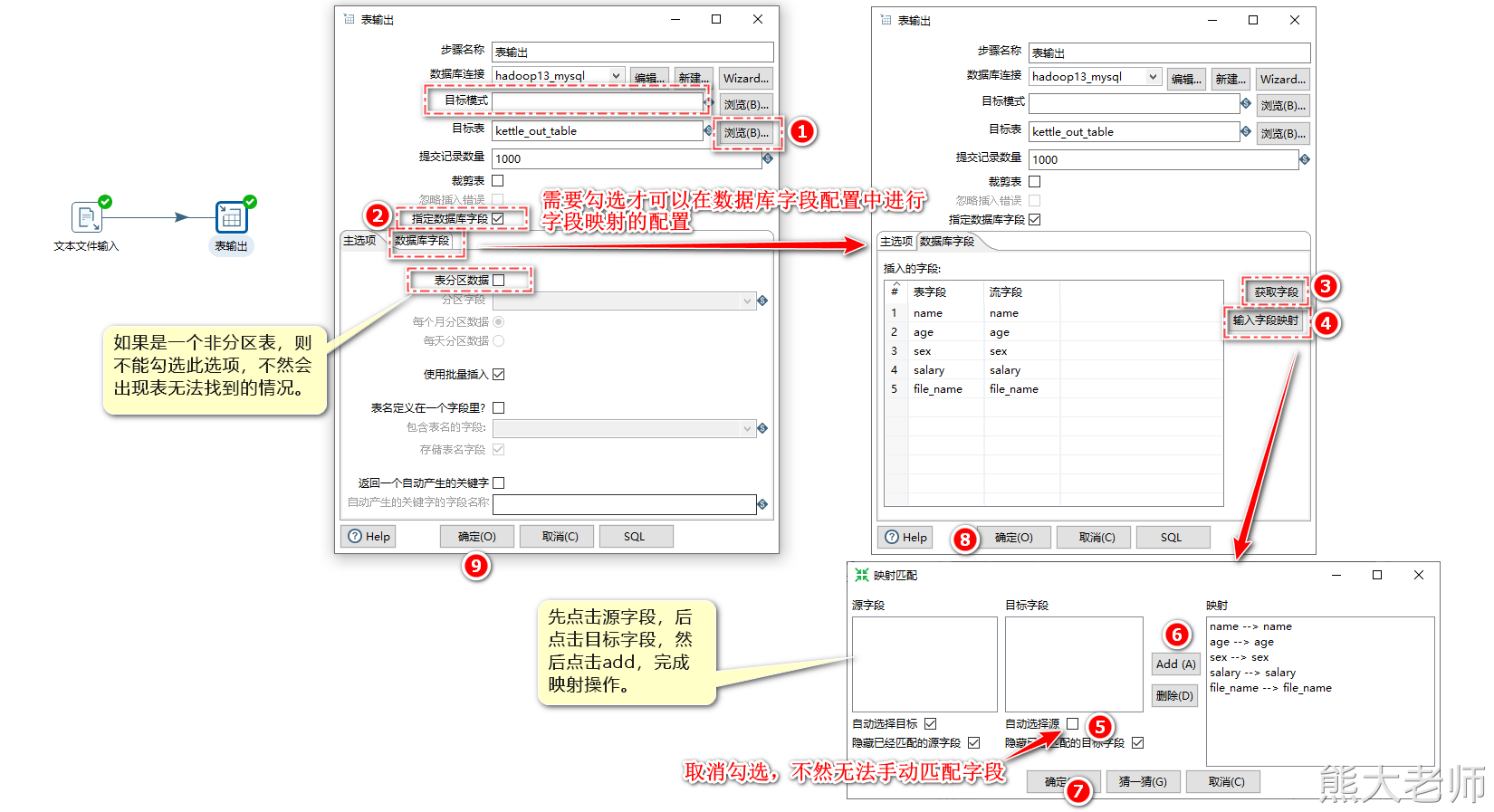
4) 表输出
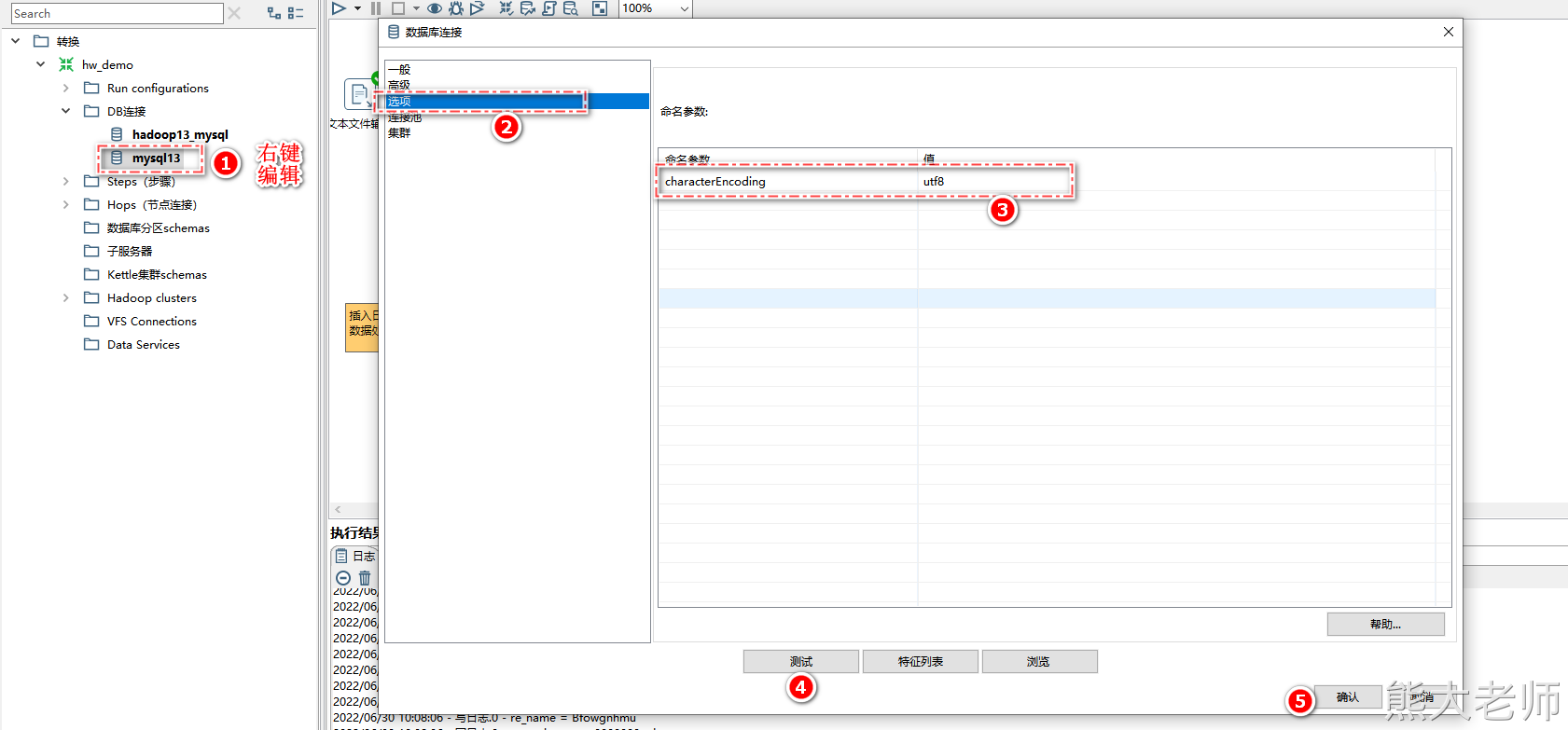
注意:如果数据中存在中文,则需要在数据库配置处添加命名参数
命名参数:characterEncoding
值:utf8
3. 转换
1) Concat fields
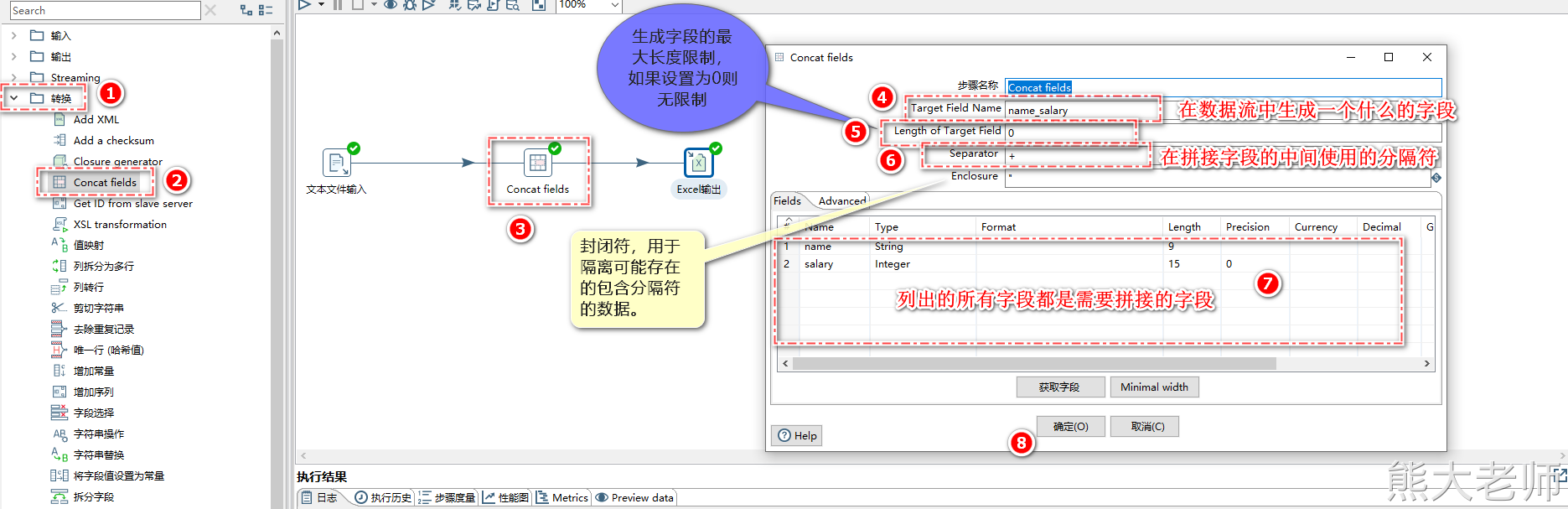
在输出的时候,记得设定合并后的字段的长度不能太短
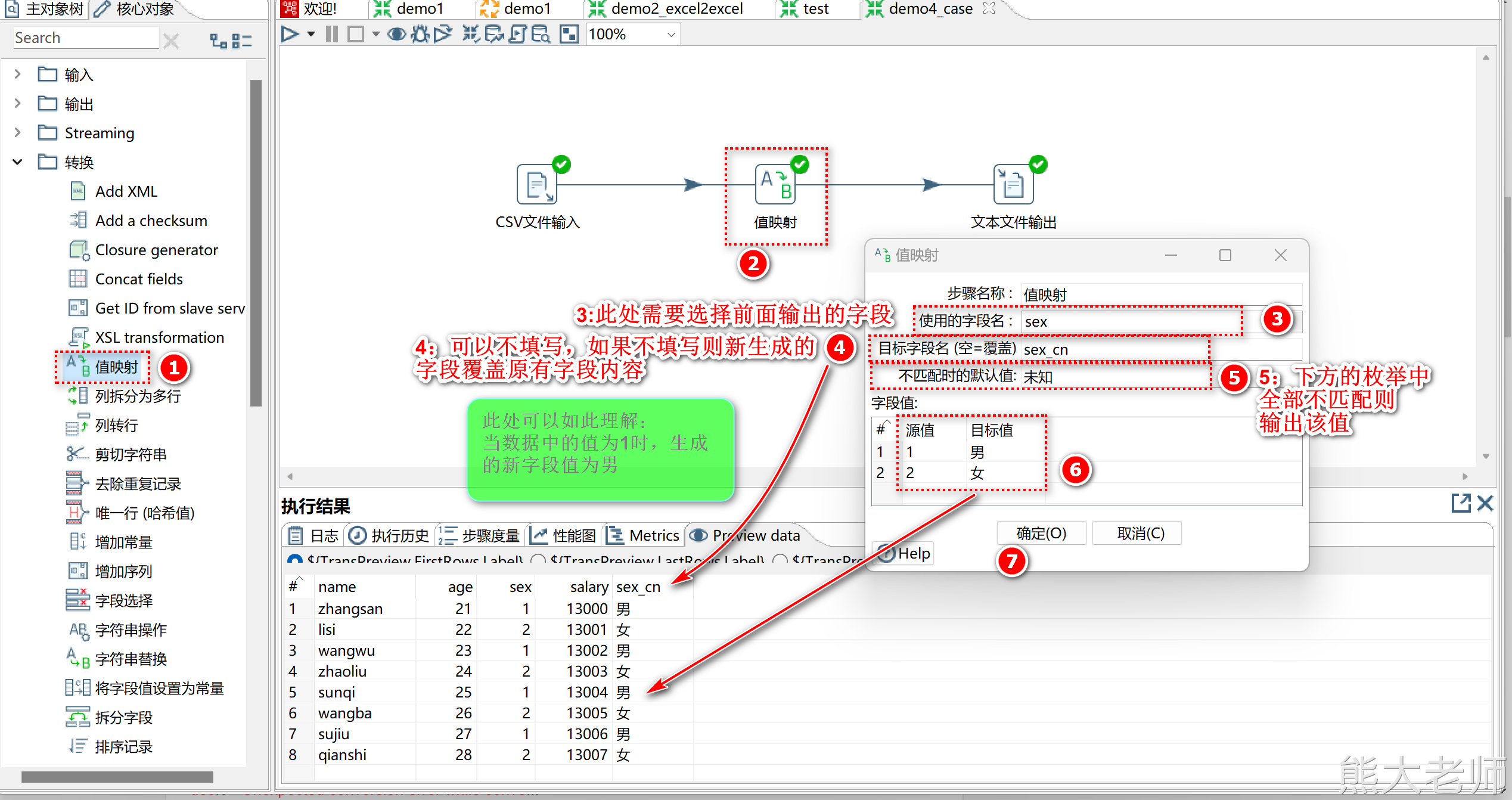
2) 值映射
当遇到需要将某个字段中的值,根据值的内容来进行数据映射的时候,使用【值映射】步骤
类似于 0 代表男 1 代表女,输出的时候不输出 0 或者1 ,而是输出 男或者女
要求:在值映射的组件中进行字段值的配置时,“源值”与“目标值”的字段类型需要一致。
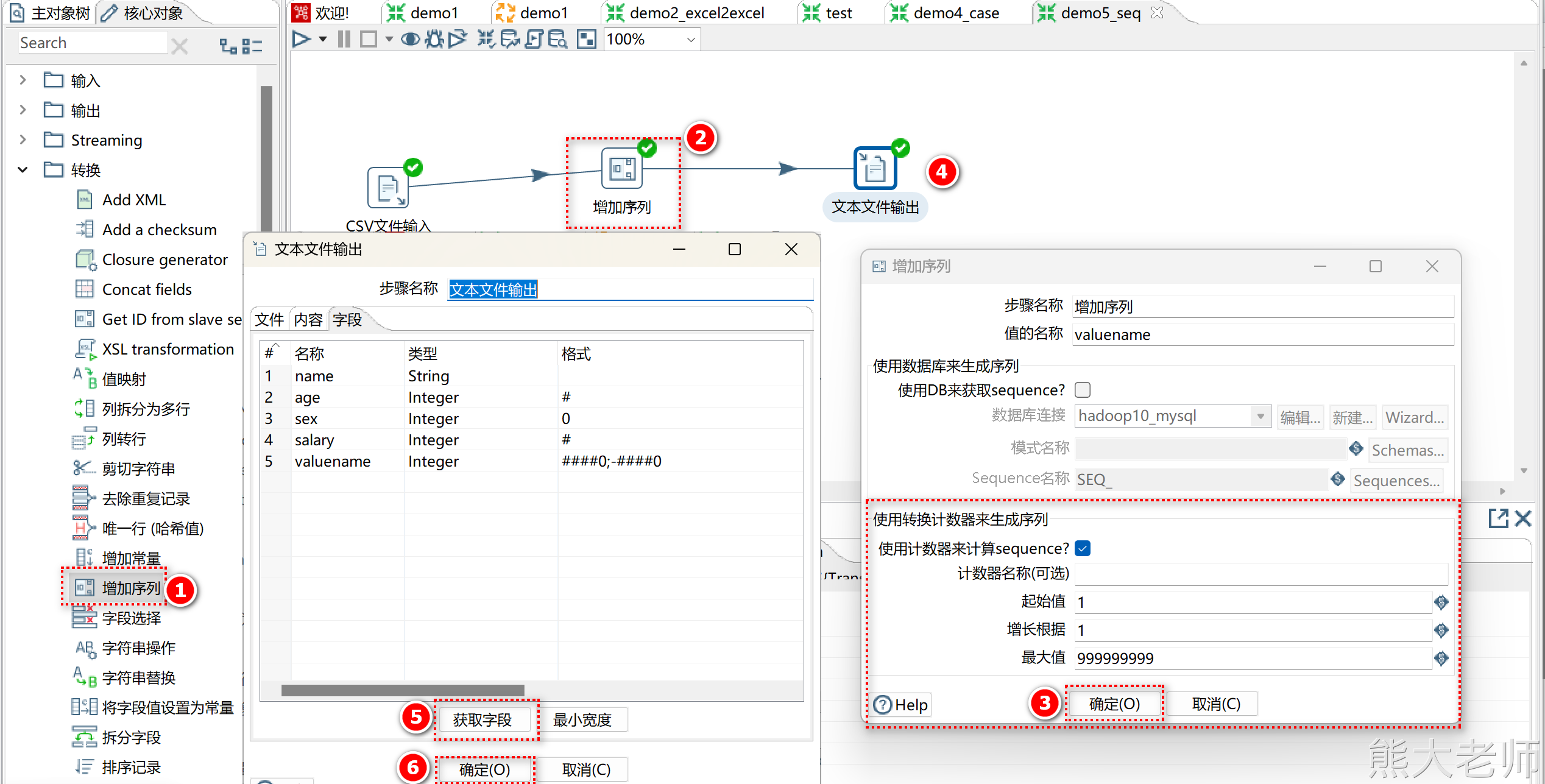
3) 增加序列
相当于 row_number() over()
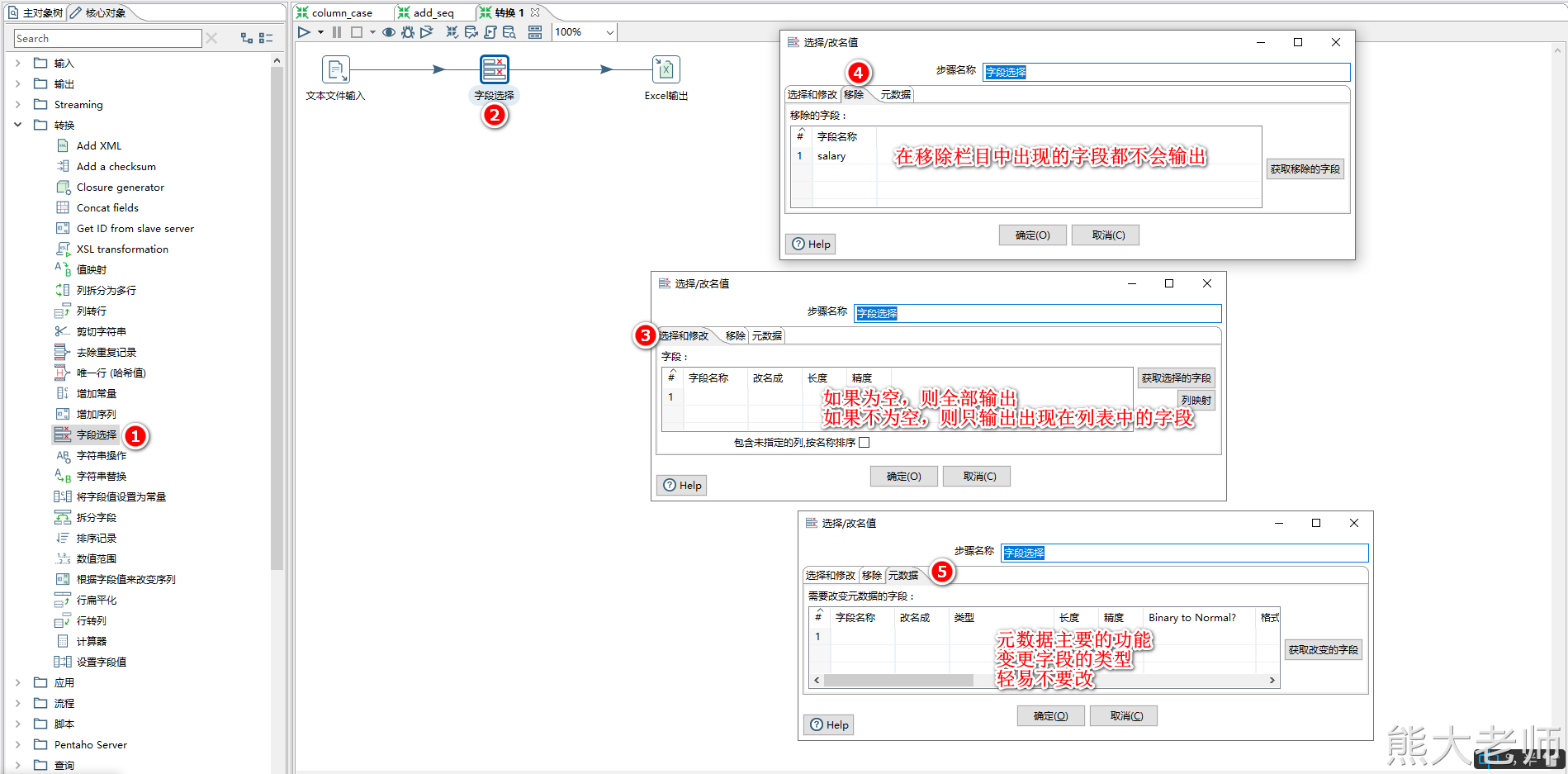
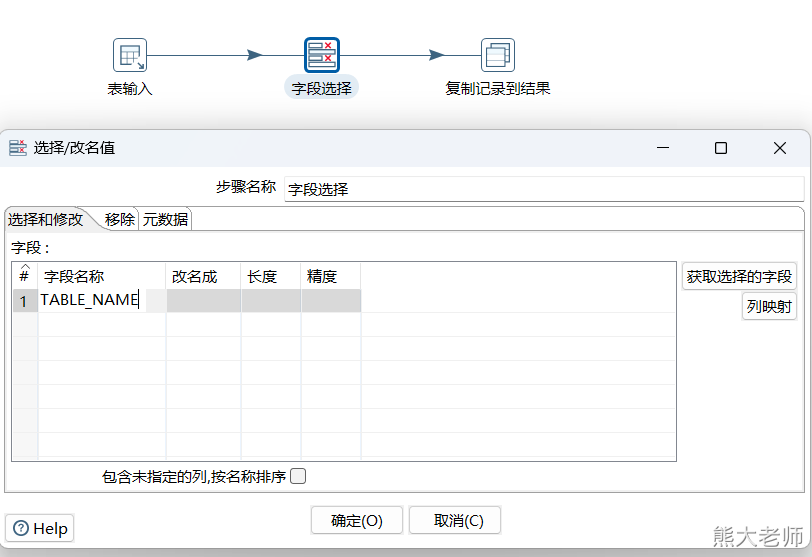
4) 字段选择
当需要对抽取的数据只获取其中的某几列字段的时候,可以使用字段选择step
【字段选择】step还可以对字段的名称进行更改,以及变更其数据类型
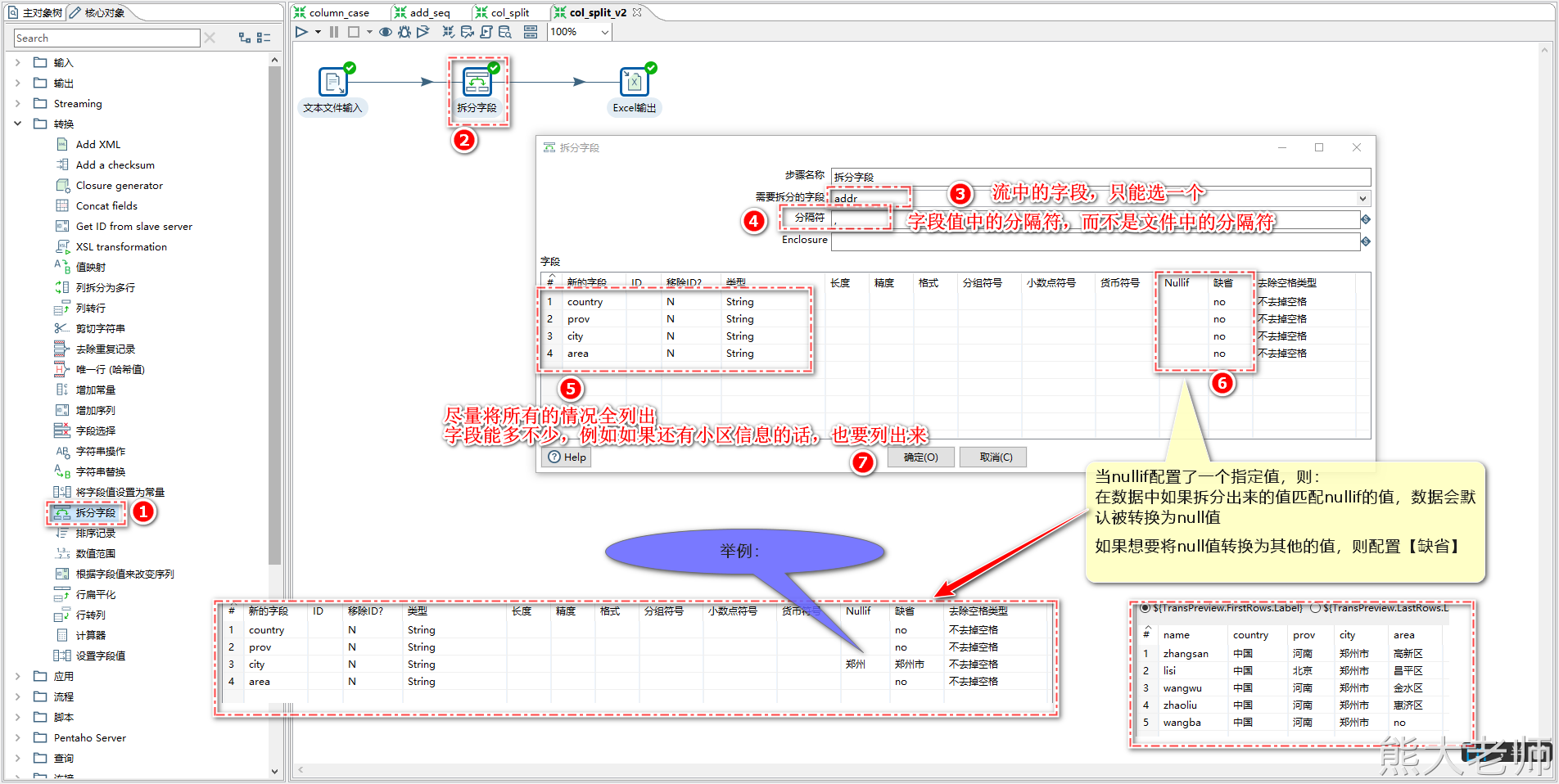
5) 拆分字段
如果遇到需要将数据由一个字段拆分成多个字段的需求,可以使用【拆分字段】step
比如,有字段数据如下:
“中国,河南,郑州,高新区”
“中国,北京,,昌平区”
将其拆分成:
国家 | 省份 | 地市 | 区 |
中国 | 河南 | 郑州 | 高新区 |
中国 | 北京 | 昌平 |
准备数据:
zhangsan 中国,河南,郑州,高新区 lisi 中国,北京,,昌平区 wangwu 中国,河南,郑州,金水区 zhaoliu 中国,河南,郑州,惠济区
6) 列拆分为多行(炸裂)
当需要将输入的数据进行“炸裂”处理时,可以使用【列拆分为多行】step
源数据:
zhangsan 中国,河南,郑州,高新区 lisi 中国,北京,,昌平区 wangwu 中国,河南,郑州,金水区 zhaoliu 中国,河南,郑州,惠济区 wangba 中国,河南,郑州
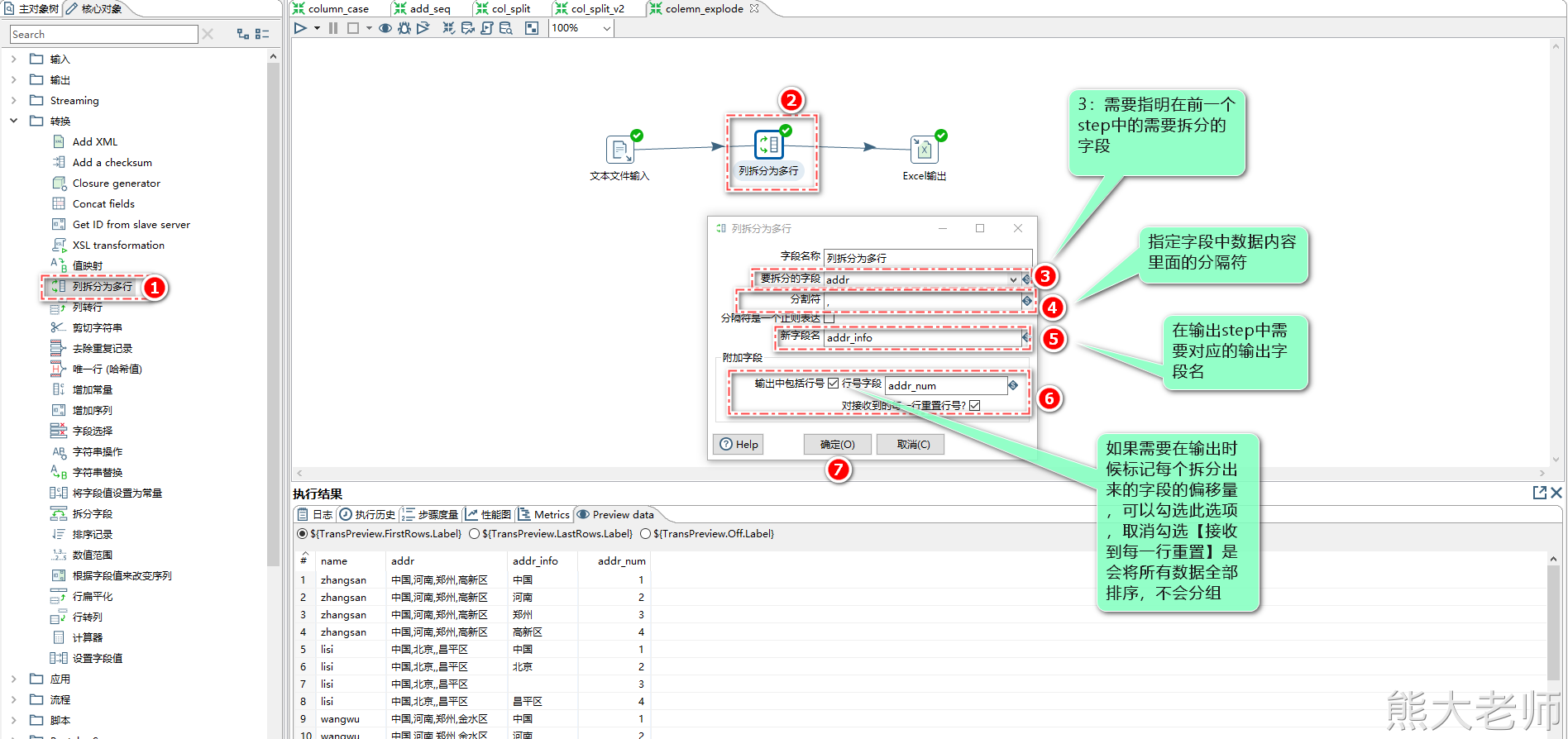
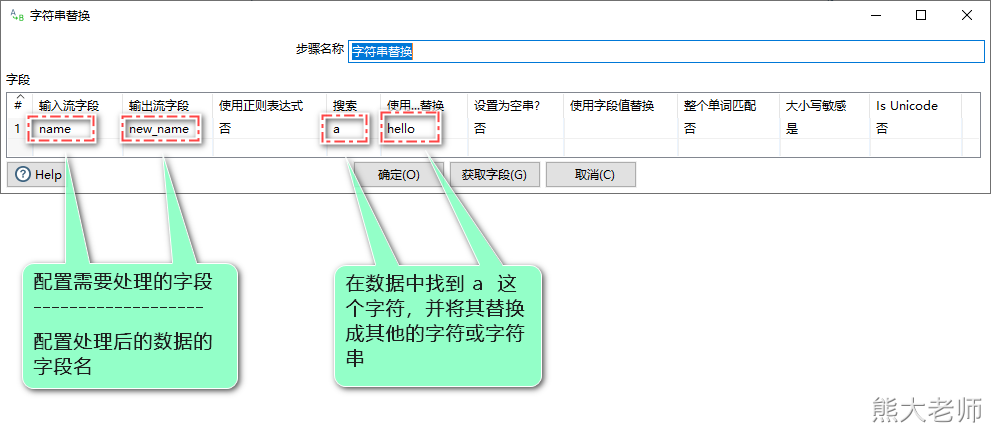
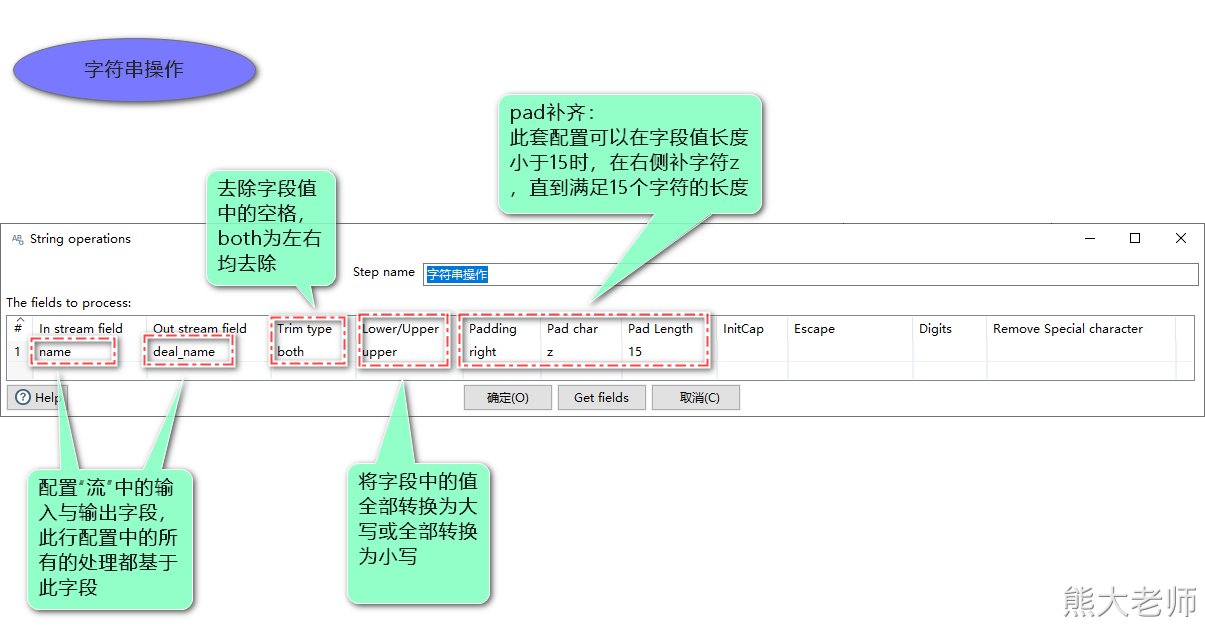
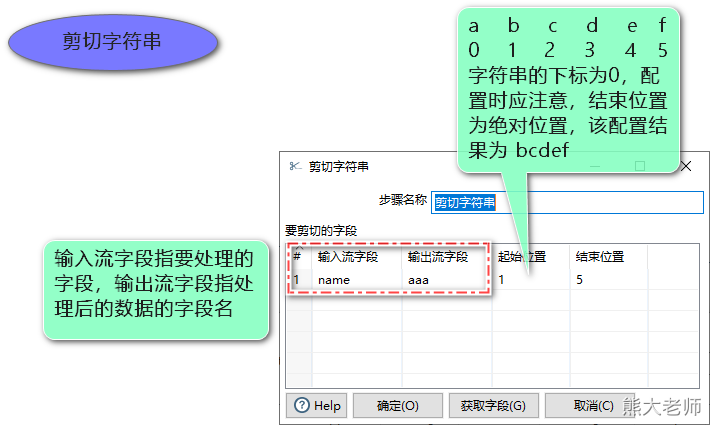
7)字段处理step汇总
字符串替换
字符串操作
剪切字符串
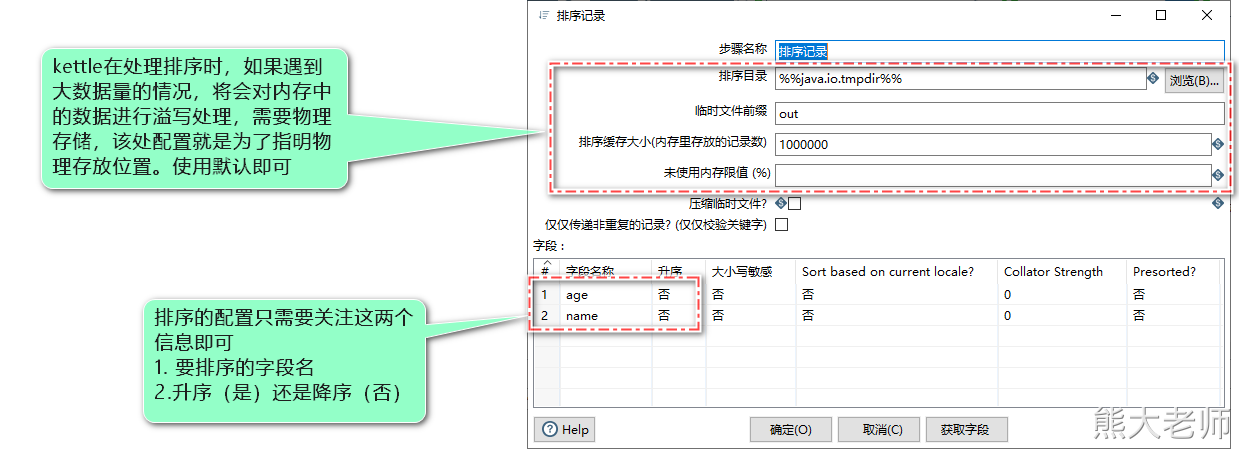
8)排序记录
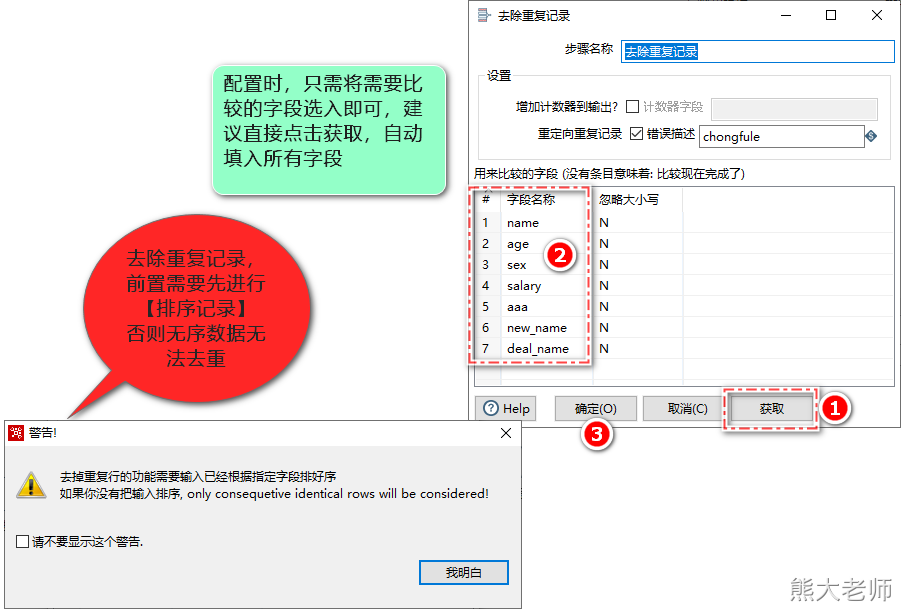
9)去除重复记录
4. 应用
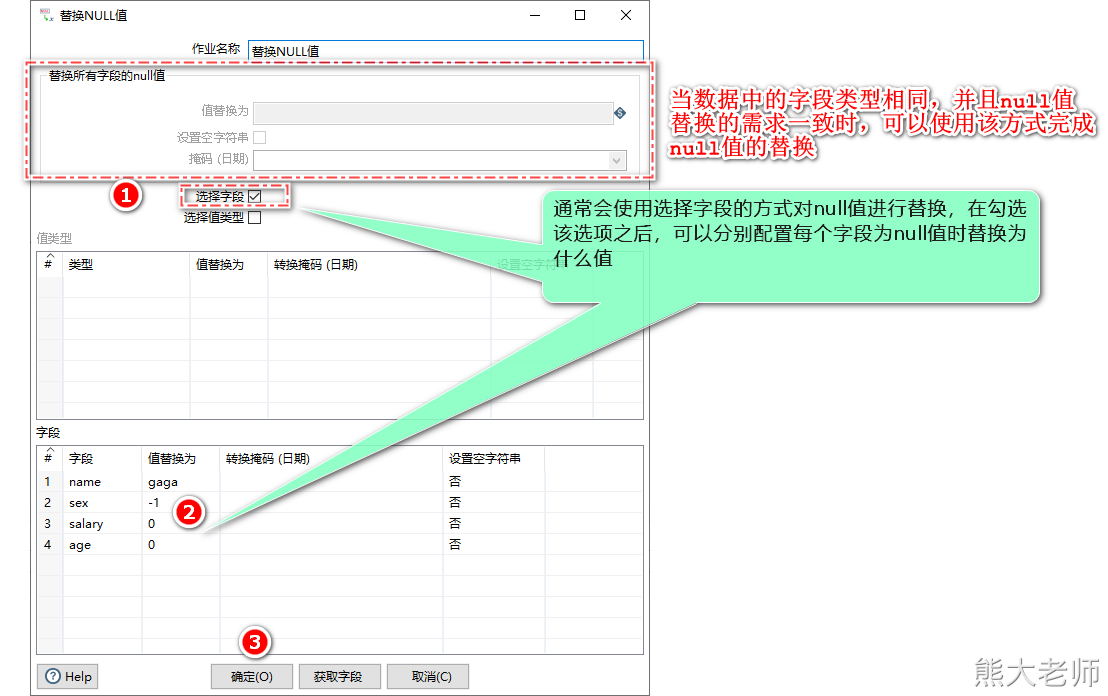
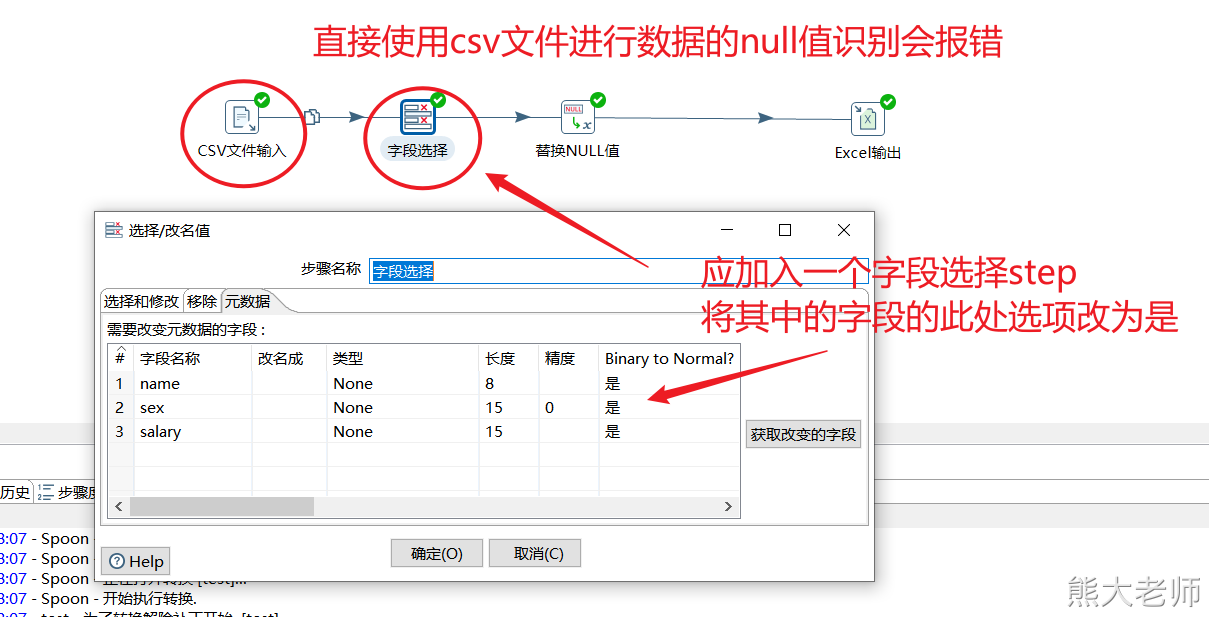
1) 替换null值
将数据流中某些为空的字段值替换成指定的值
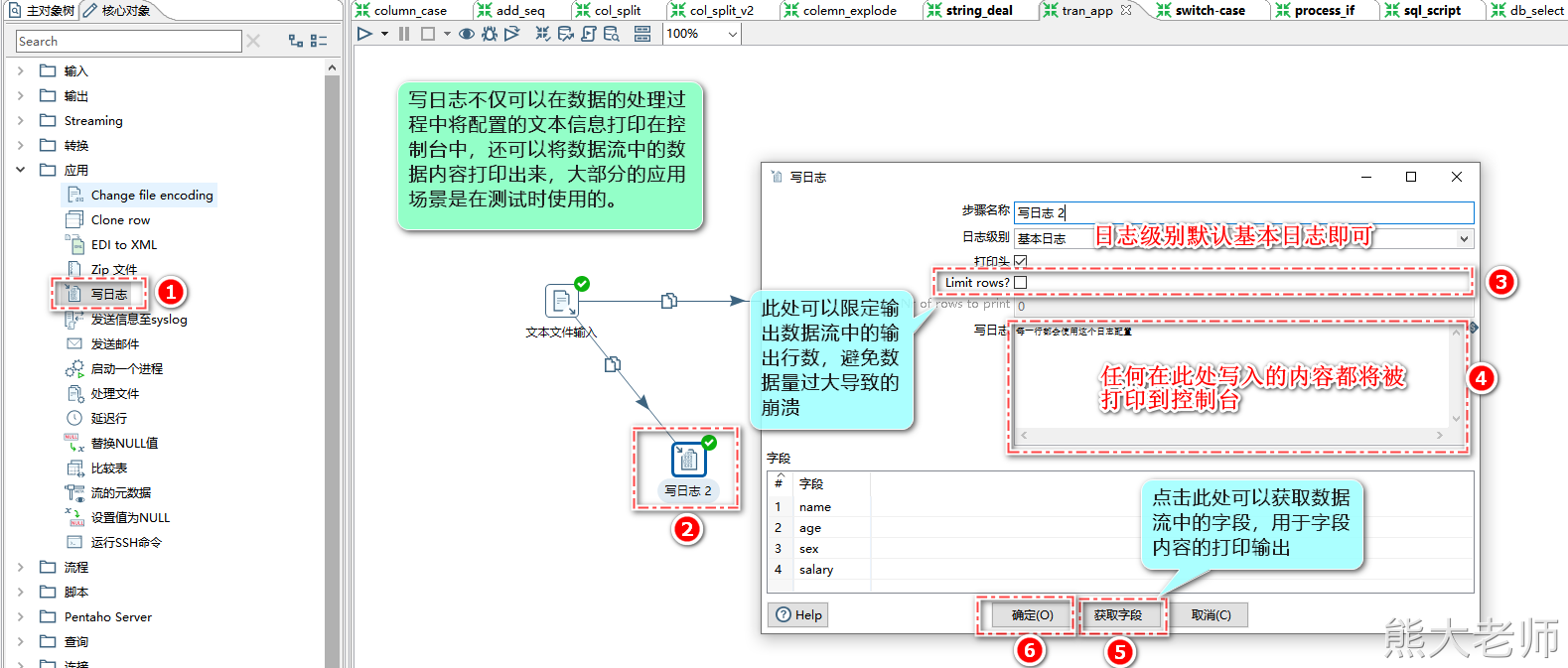
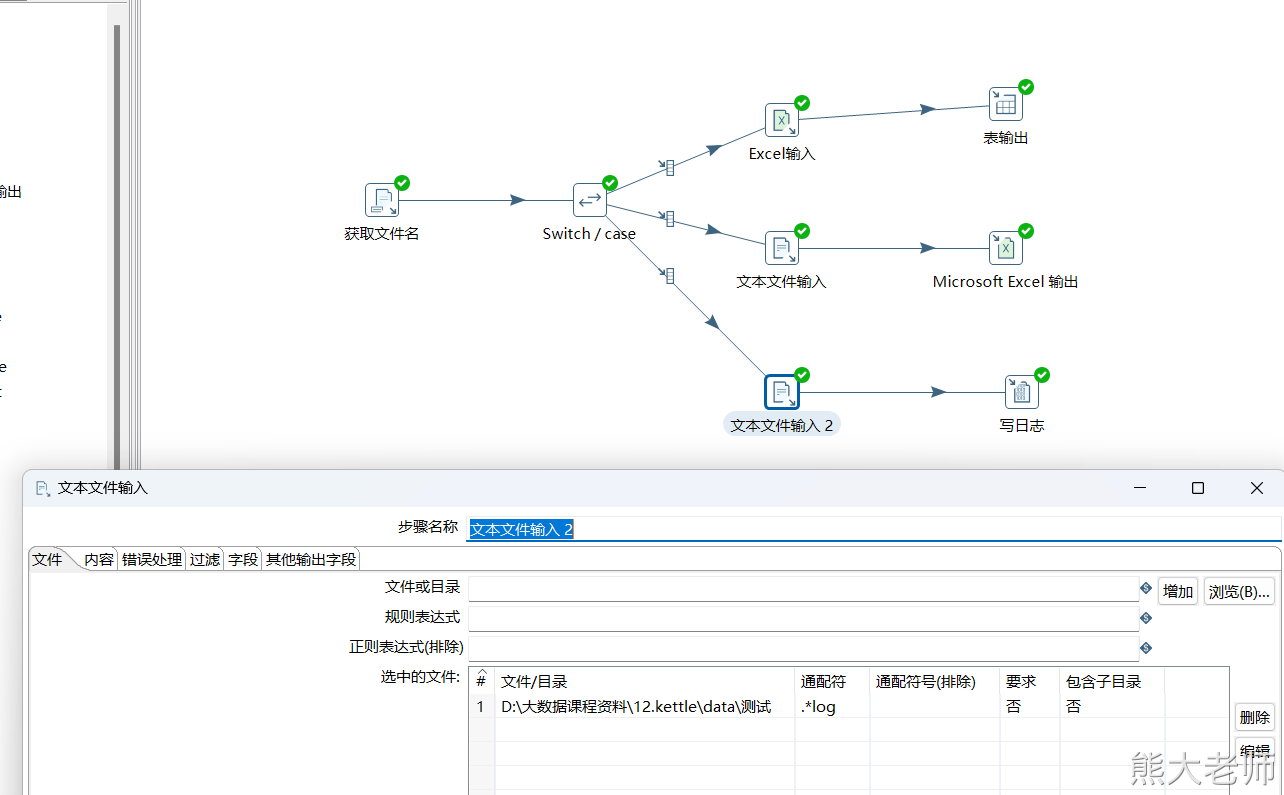
2)写日志
通常在调试阶段使用写日志step,用来查看数据的流通情况
注意:在启动任务时,会出现启动配置,此时,启动配置中的日志级别需要大于等于任务中【写日志】step中配置的日志级别。
5. 流程
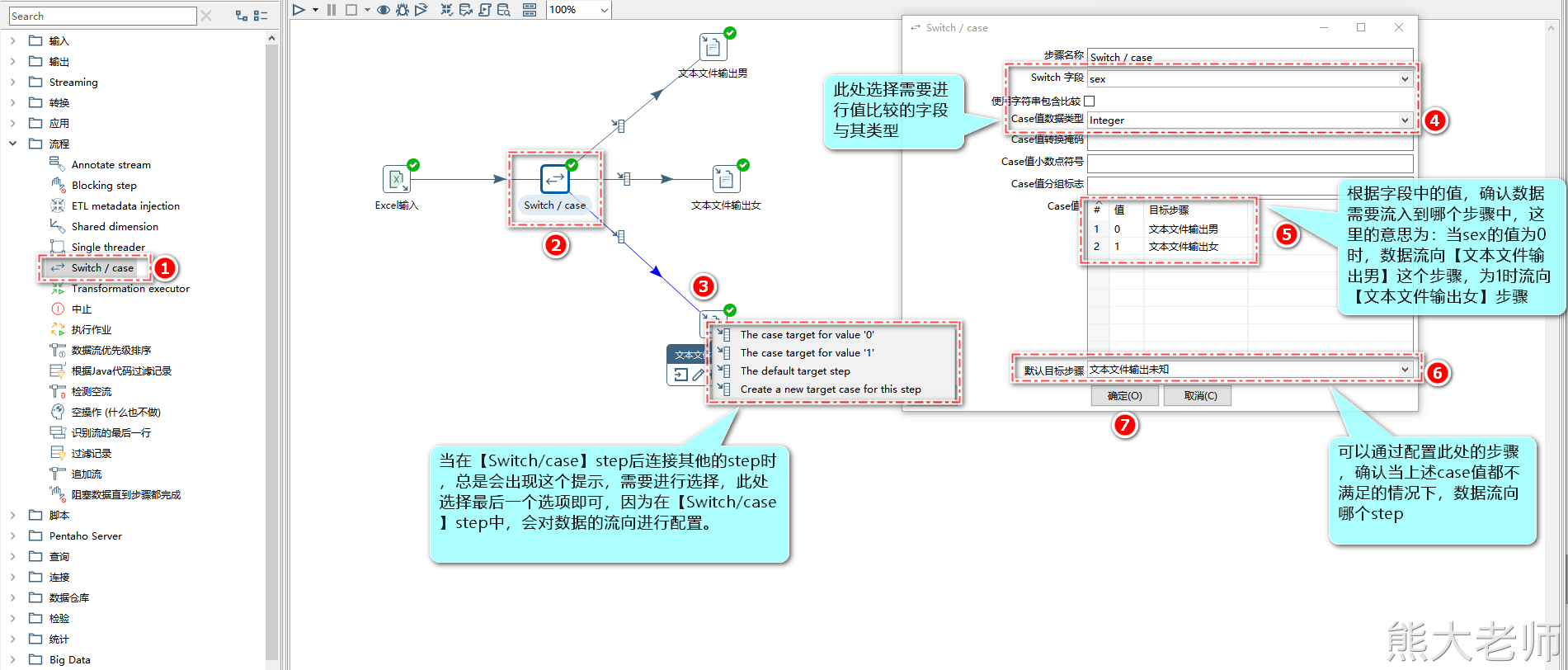
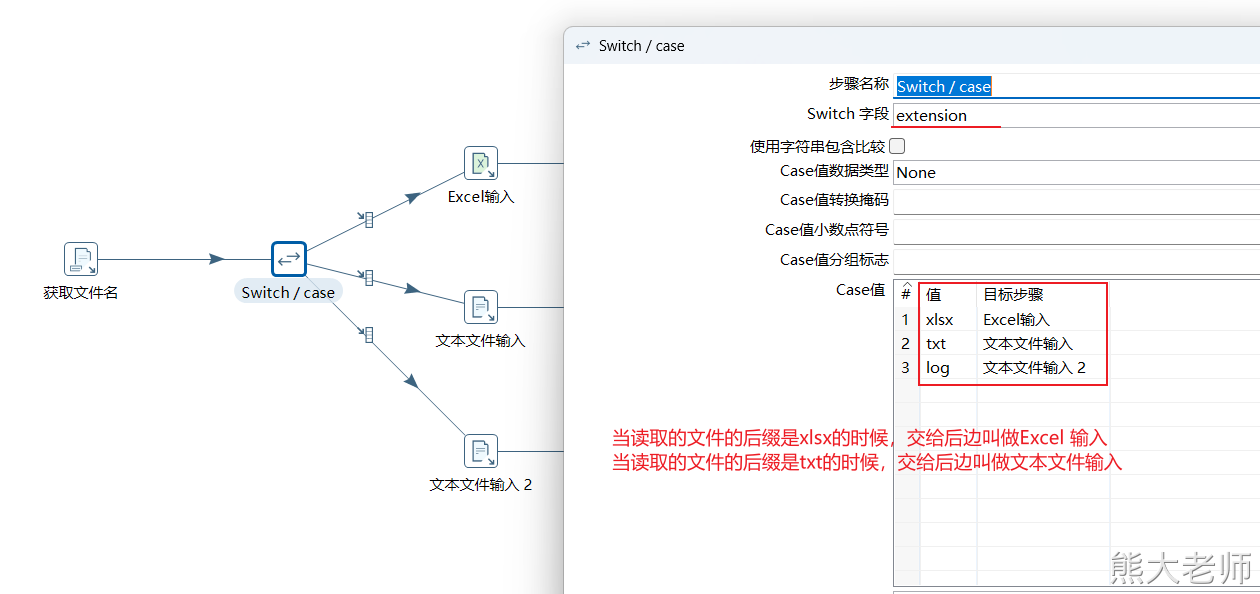
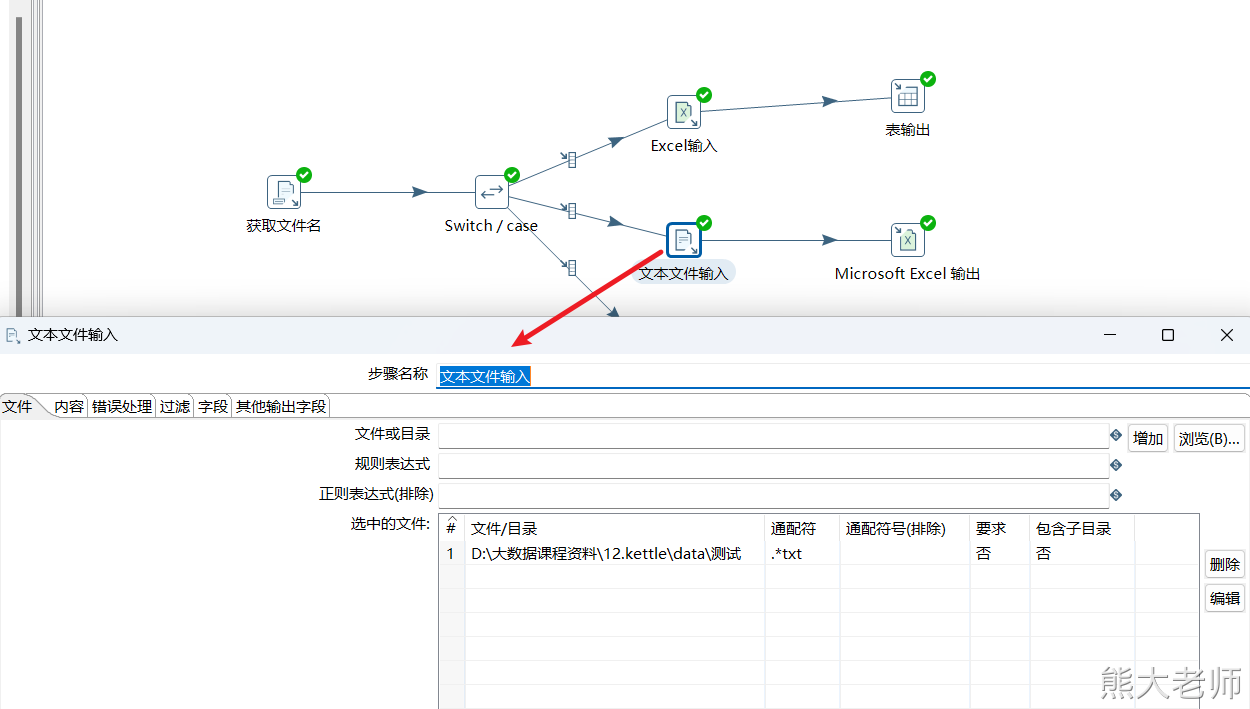
1) switch/case
“Switch/case”类似Java中的Switch...case...操作,可以根据匹配不同的值做不同的操作,可以让数据流由一路到多路
注意:该step只能通过相等的判断对数据进行分流
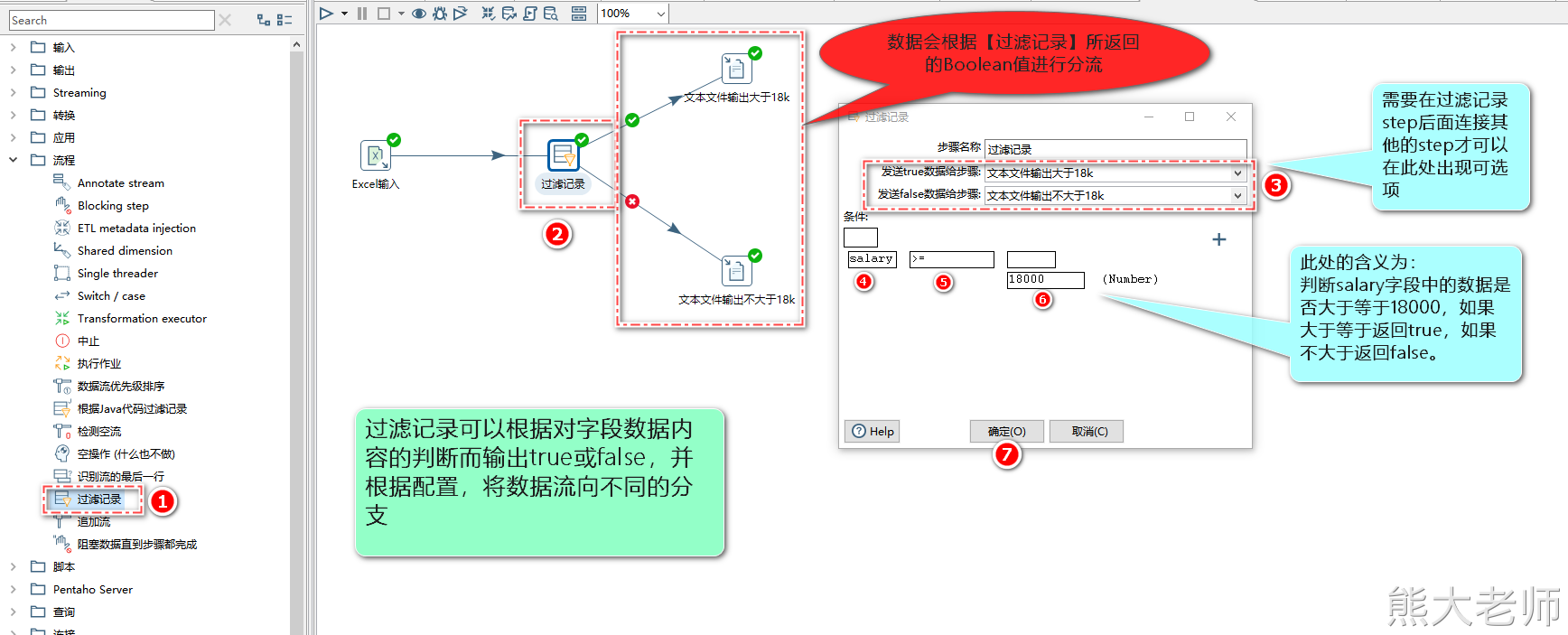
2) 过滤记录
“过滤记录”可以根据指定条件获取true或者false让数据流数据由一路到两路
6. 脚本
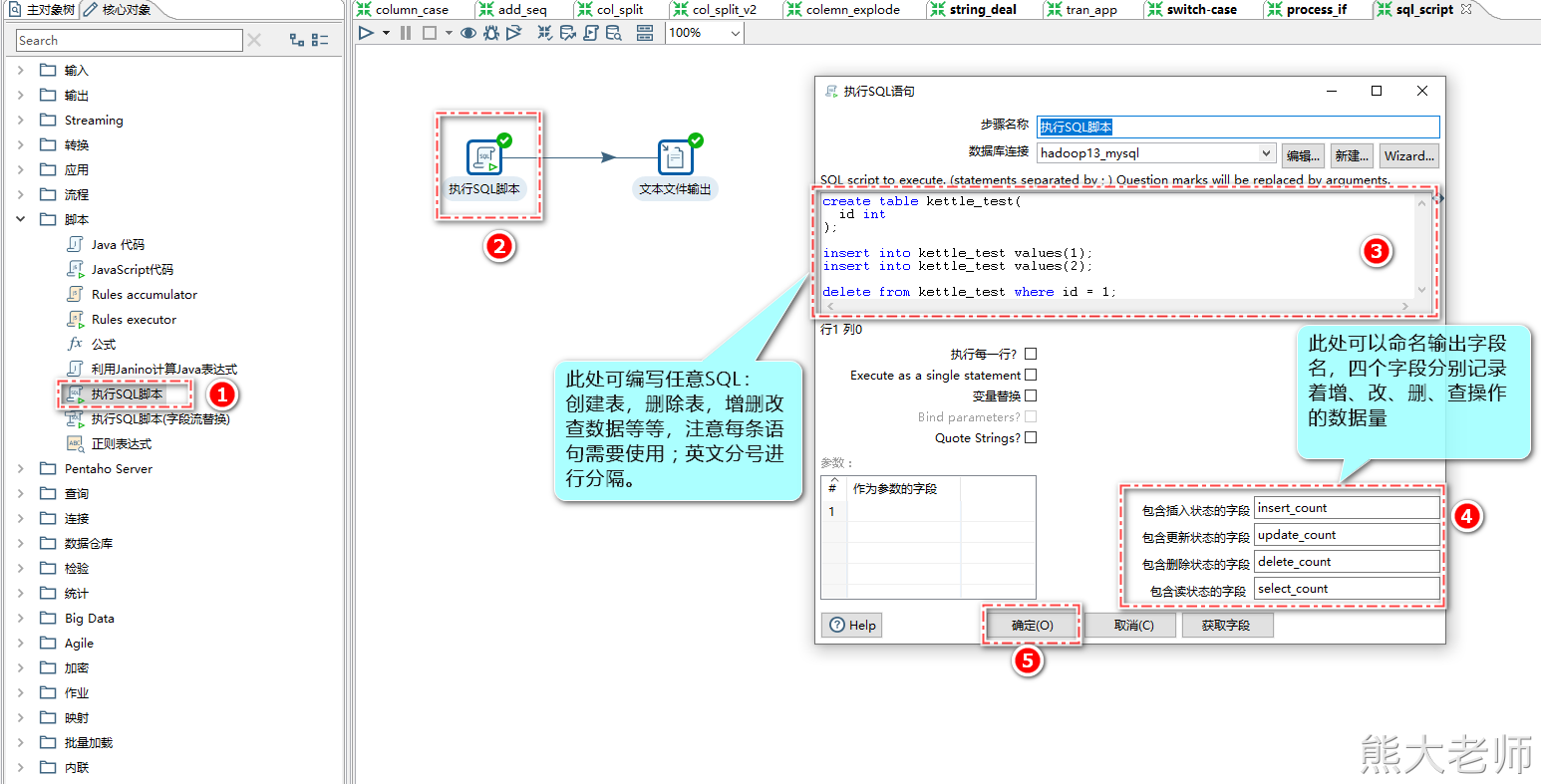
1) 执行sql脚本
“执行SQL脚本”可以执行自己定义的SQL语句,例如执行一个update语句,用来更新某个表中的数据。
7. 查询
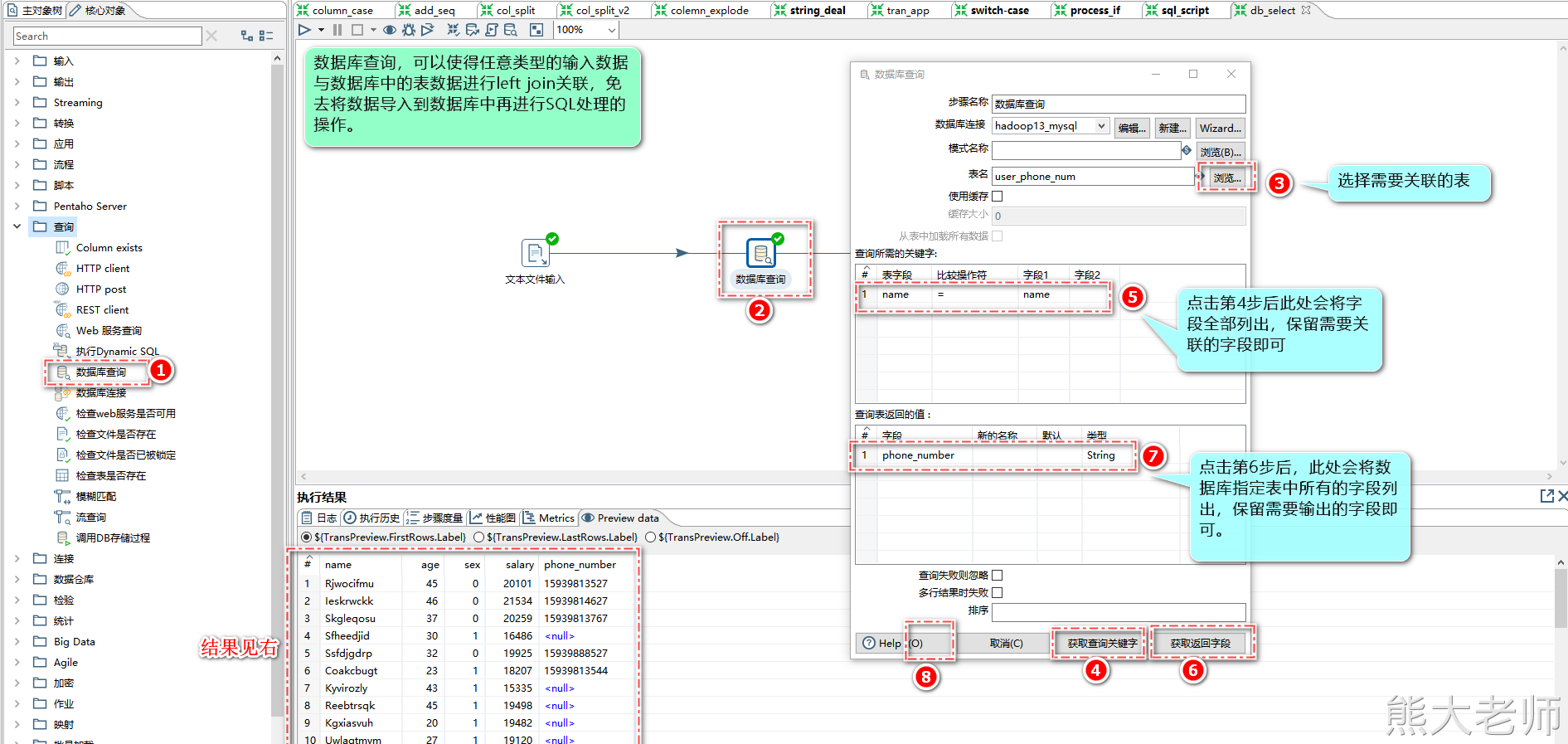
1) 数据库查询
当在处理一个文本文件或者Excel文件的时候,需要去关联数据库中的数据,将数据库中的数据(字段)关联出来,作为输出,可以使用【数据库查询】step
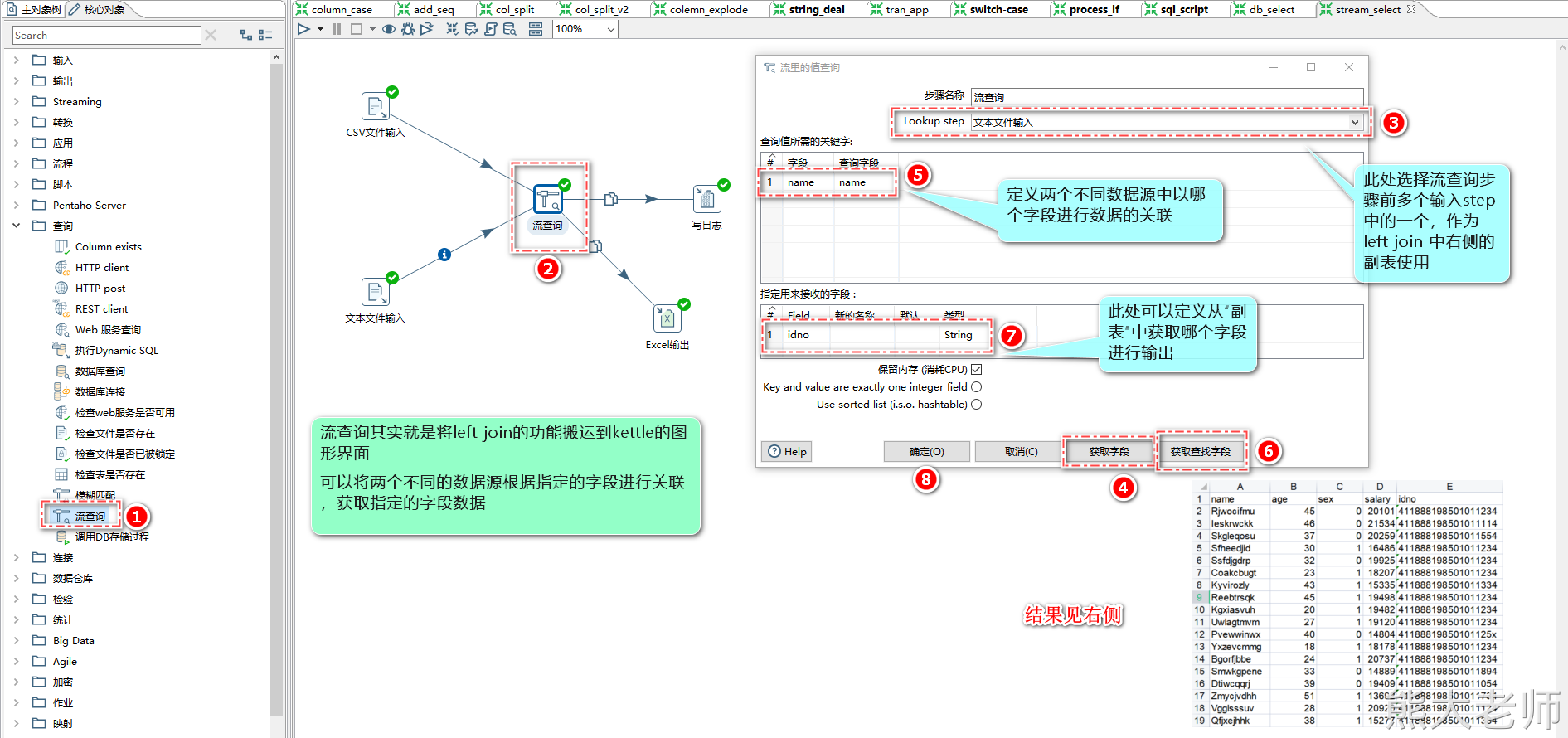
2) 流查询
在【数据库查询】查询的基础上,流查询可以将任意类型的数据进行融合关联,完成指定需求字段的输出。
比如:可以将两个文本文件一起完成left join的操作
8. 连接
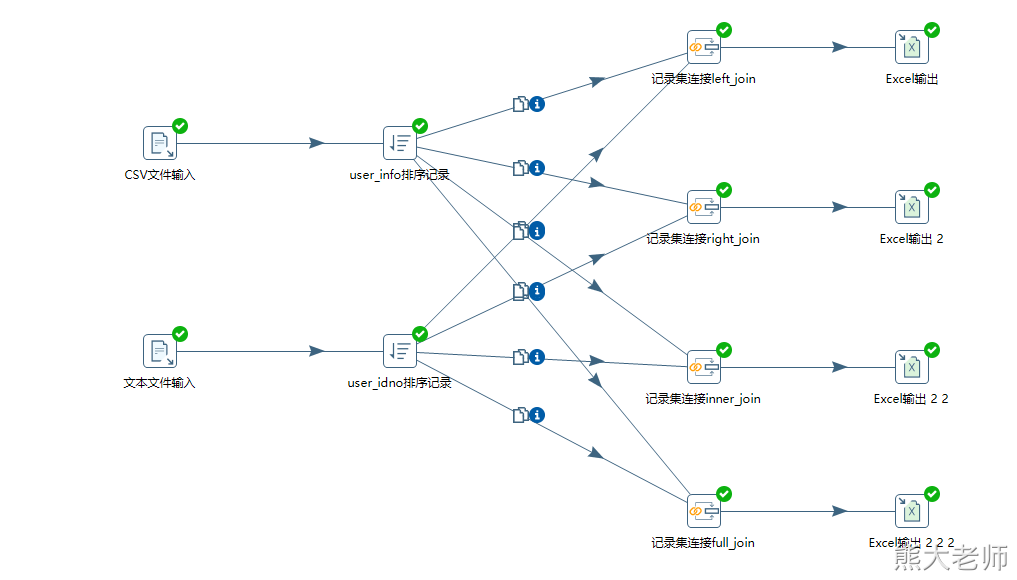
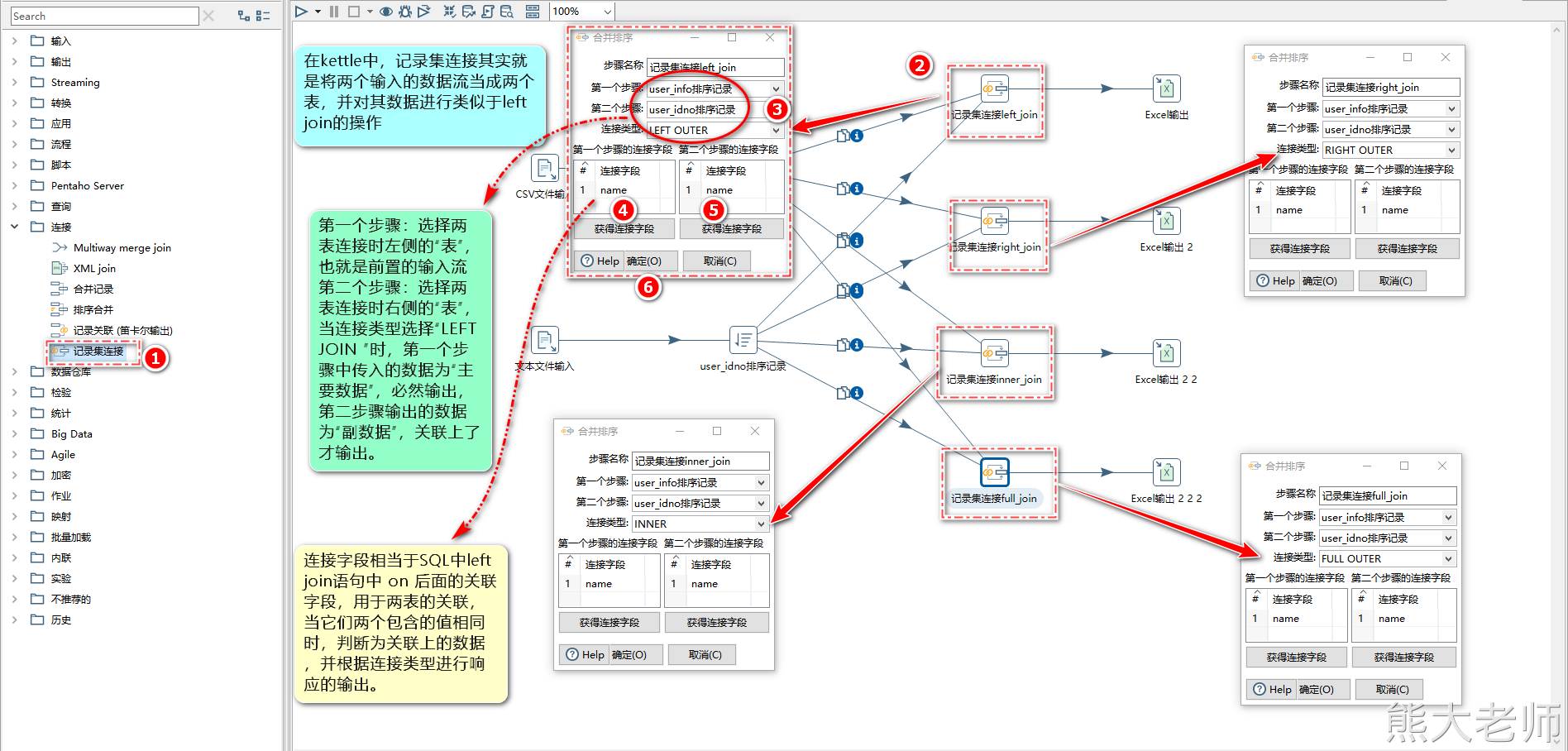
1) 记录集连接
“记录集连接”可以做类似数据库中左连接、右连接、内连接、外连接操作。在对流数据进行连接之前,需要对记录集进行排序
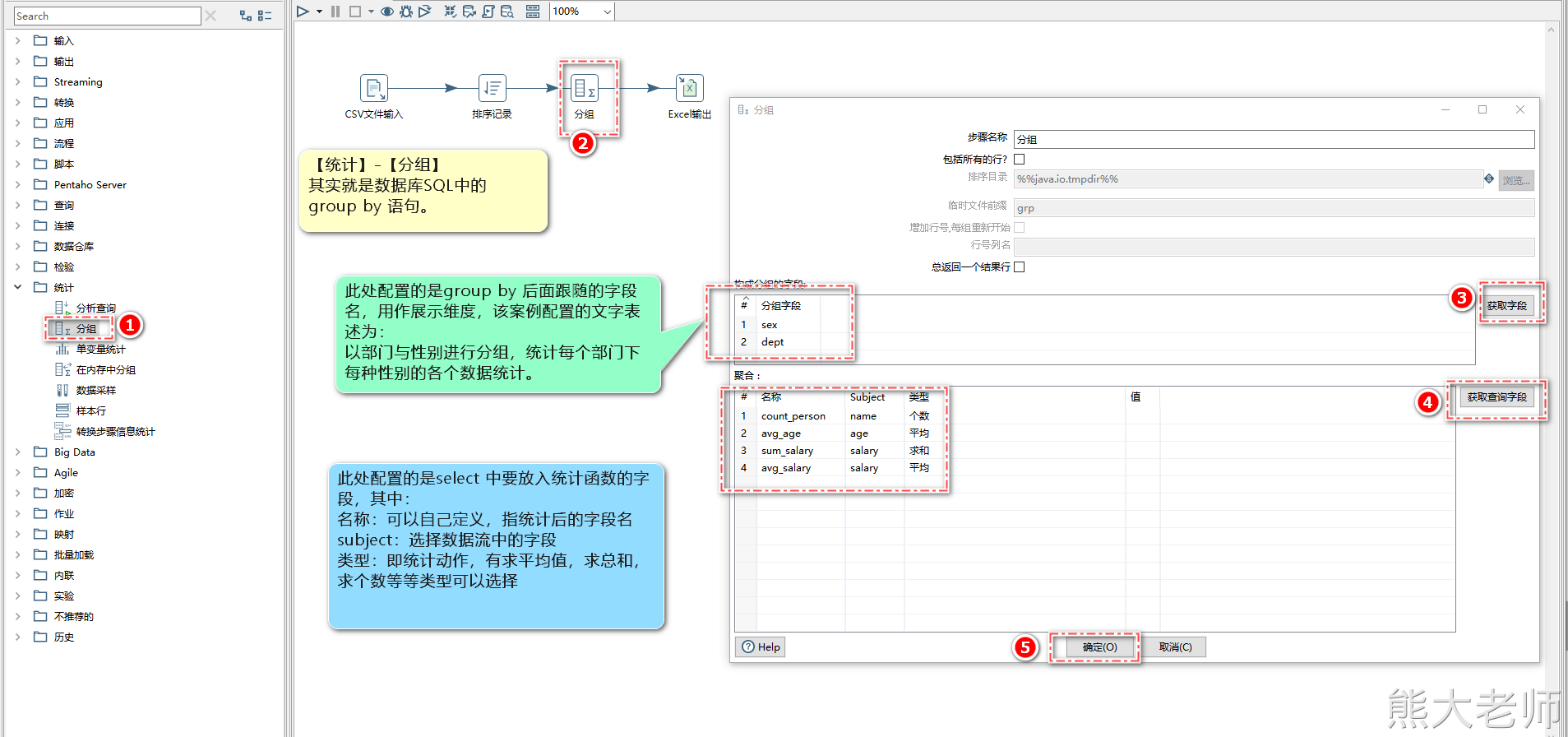
9. 统计-分组
“分组”是按照某一个或者某几个字段进行分组,同时可以将其余字段按照某种规则进行合并。需要对记录集进行排序。
根据需求来进行认识【统计】-【分组】step的功能:
统计一个部门下,每个性别的平均工资、工资总和以及平均年龄
测试数据:
name,age,sex,salary,dept Rjwocifmu,45,0,20101,dept_A Ieskrwckk,46,0,21534,dept_A Skgleqosu,37,0,20259,dept_A Sfheedjid,30,1,16486,dept_A Ssfdjgdrp,32,0,19925,dept_A Coakcbugt,23,1,18207,dept_A Kyvirozly,43,1,15335,dept_A Reebtrsqk,45,1,19498,dept_A Kgxiasvuh,20,1,19482,dept_A Uwlagtmvm,27,1,19120,dept_A Pvewwinwx,40,0,14804,dept_B Yxzevcmmg,18,1,18178,dept_B Bgorfjbbe,24,1,20737,dept_B Smwkgpene,33,0,14889,dept_B Dtiwcqqrj,39,0,19409,dept_B Zmycjvdhh,51,1,13692,dept_B Vgglsssuv,28,1,20920,dept_B Qfjxejhhk,38,1,15277,dept_B Wbeduyvjj,23,0,13080,dept_B Tasongucb,25,0,21229,dept_B Vvxnjkuej,36,1,17332,dept_B Yvkkwqhza,32,0,21576,dept_B Wpaeogpck,38,0,16441,dept_B Ywwxagilk,24,1,14263,dept_B Qvzbeseqe,53,1,20635,dept_C Vasljxiee,37,0,21092,dept_C Ualdzgpfi,32,0,20405,dept_C Kpfsxsjve,49,1,17139,dept_C Tugooglcv,37,1,15113,dept_C Smclndumc,32,0,13602,dept_C Bfowgnhmu,37,1,13348,dept_C Dhhoiywlq,36,0,14326,dept_C Jtoubmytz,47,1,15001,dept_C Pjetadrpw,34,1,21592,dept_C Edyrinujs,25,0,14743,dept_C Nwtxrxlku,41,1,19254,dept_C Nimowqjzw,52,0,17987,dept_C
先说一下为什么要排序:
kettle处理数据的时候,总是将数据放入内存(类似数组)
如果要做数据统计的话:
没有顺序:需要根据分组字段,识别下一条数据是否与之相同,如果相同则算为一组进行累计,数据没有顺序的情况下,输入的数据会出现多个分组(不相邻即识别为新的分组),而导致的统计误差。
已对数据进行排序:数据在处理时,持续的遇到相同组的数据,累加器可以正常工作,对数据进行完整的统计处理。
六、作业核心对象
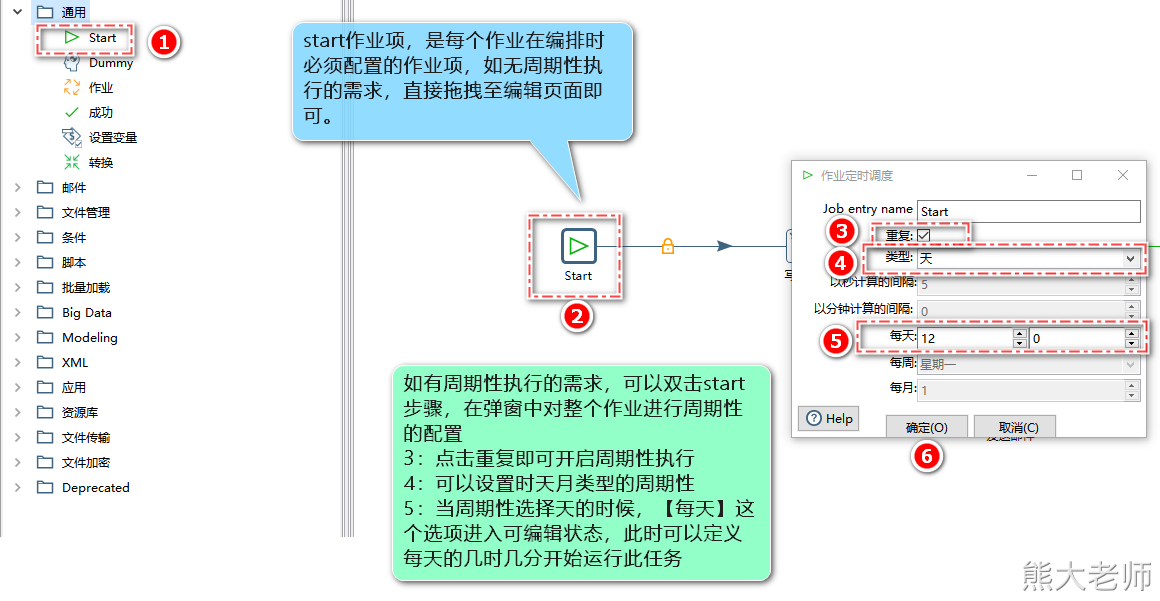
1. start
“Start”是定义作业的起点,一个作业只能有一个开始作业项。在start组件中,可以定义启动周期与定时启动。
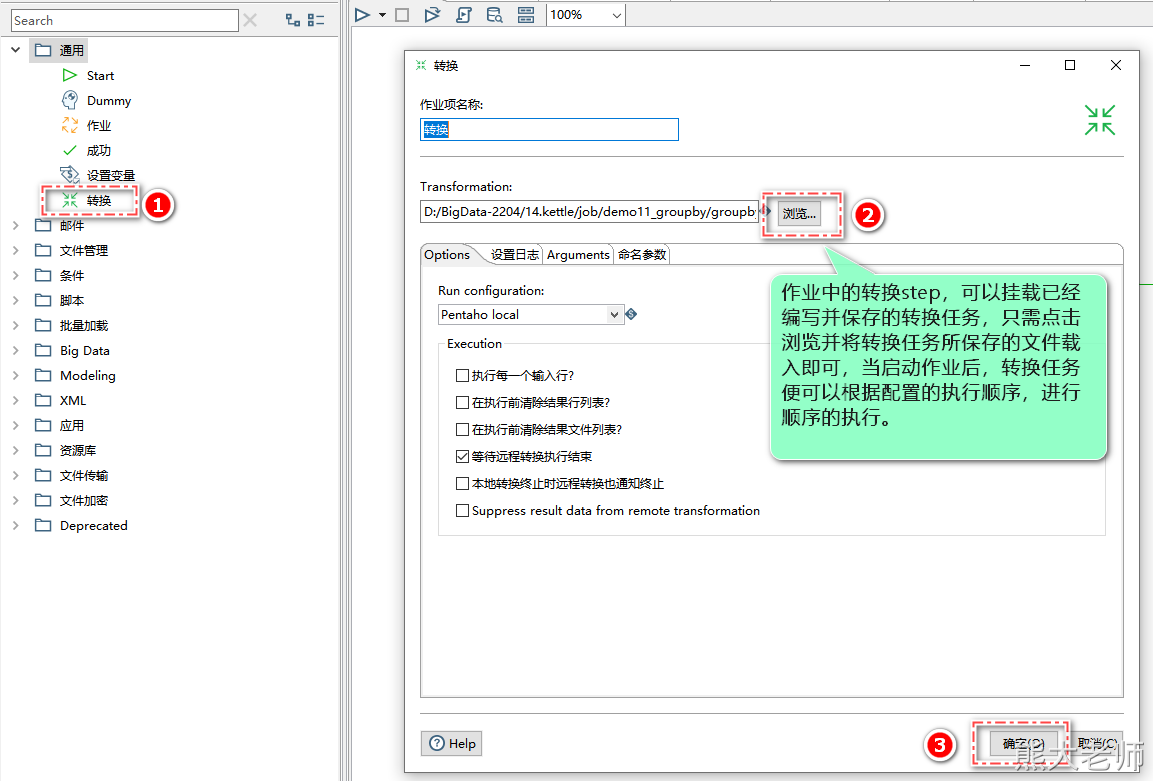
2. 转换
“转换”作业项可以包含一个转换,我们可以将详细的操作过程存入一个转换,然后包含到一个“转换”作业项中。
可以通过这种方式,来完成多个转换任务之间的顺序执行,以满足更加复杂的数据处理需求。
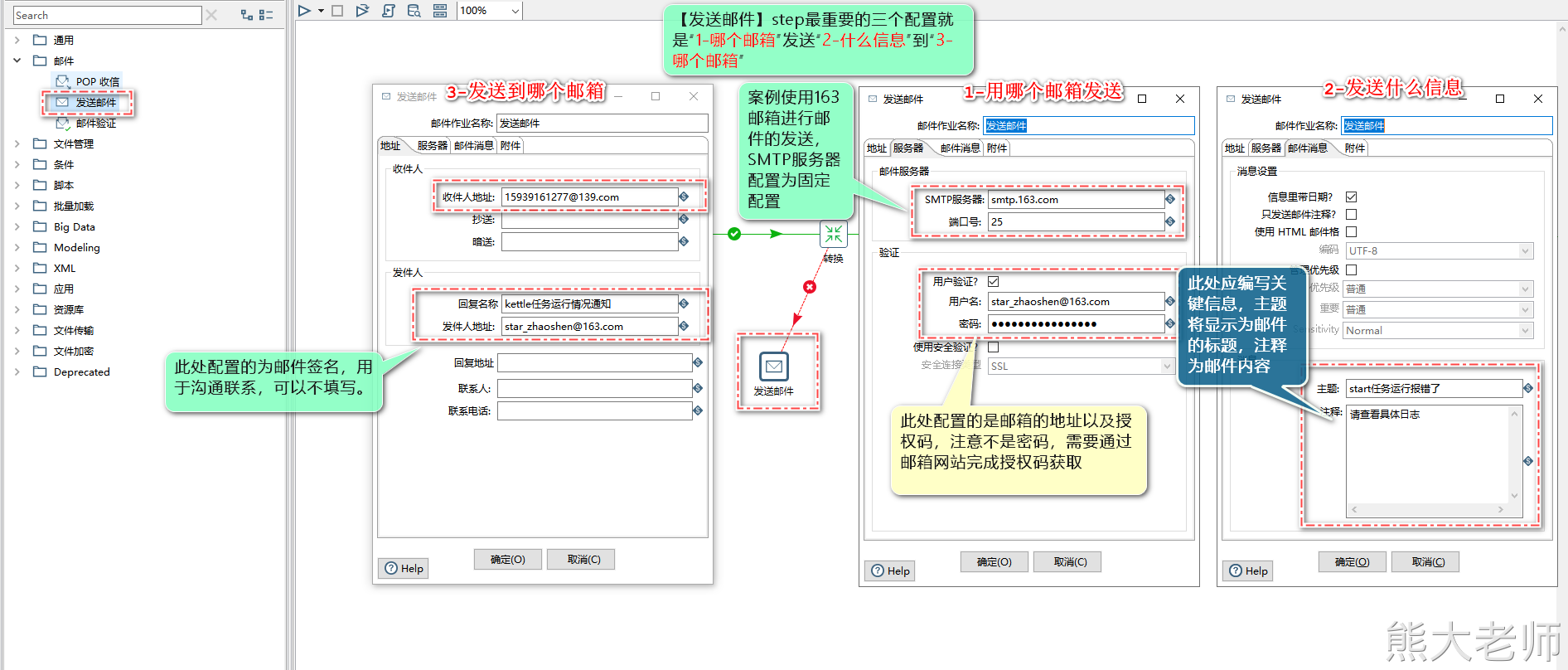
3. 邮件-发送邮件
当作业或转换运行出现问题或者运行成功等运行状态出现,维护人员想要在第一时间获取到任务的运行情况,可以通过【邮件】-【发送邮件】这个step来完成通知。
163邮箱SMTP服务器地址: smtp.163.com 端口:25
配置163邮箱时需要开启“POP3/SMTP/IMAP服务”服务,可以在163网页端进行配置。
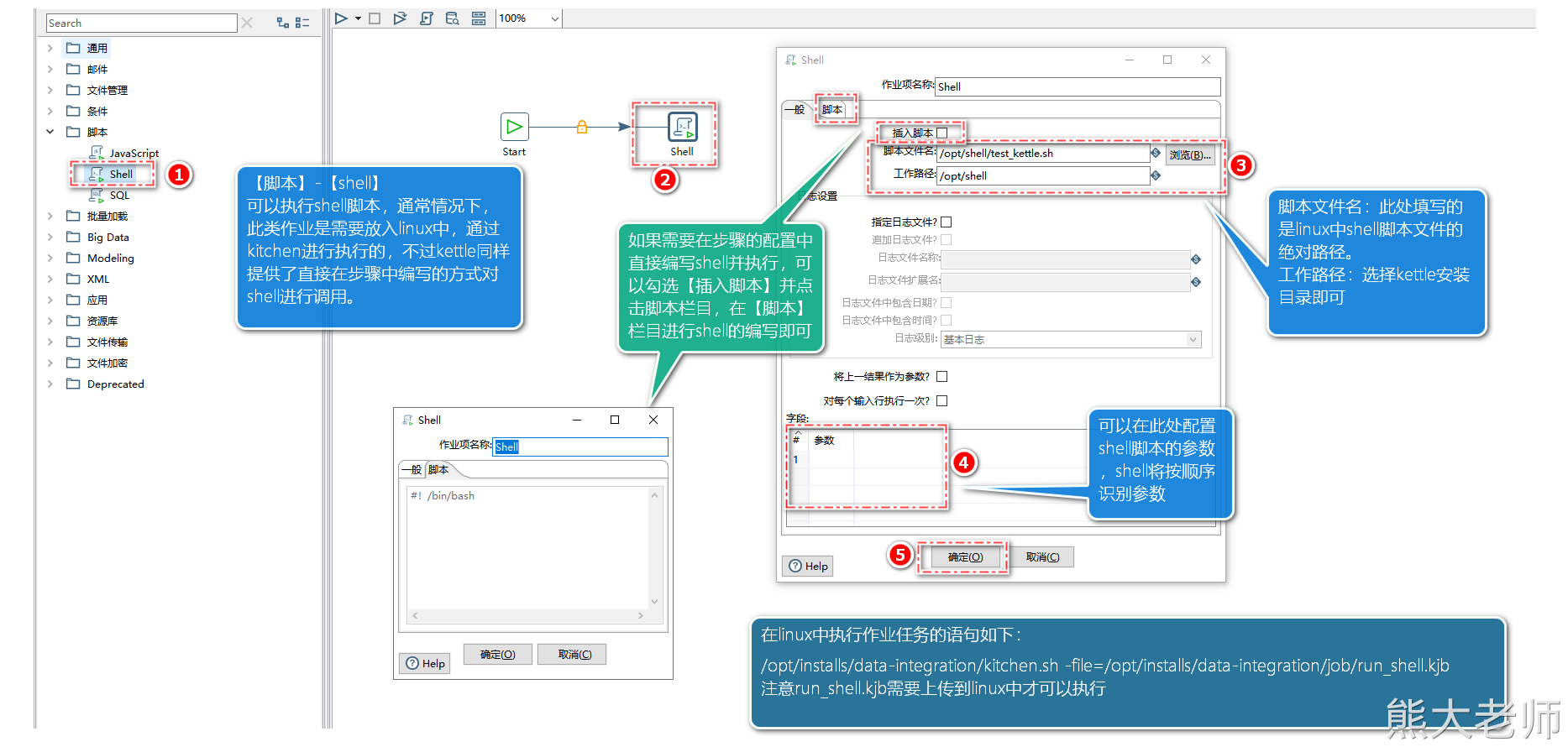
4. 执行shell脚本
首先要确认的一点是:shell一定是在linux服务器中运行的,也就意味着编写的作业是需要在linux中运行的。
而且,调用的shell也需要在linux存放。
需要注意的点:
在填写文件的时候,需要给一个绝对路径
在编写好shell脚本之后,要chmod 777 shell脚本名
七. 变量
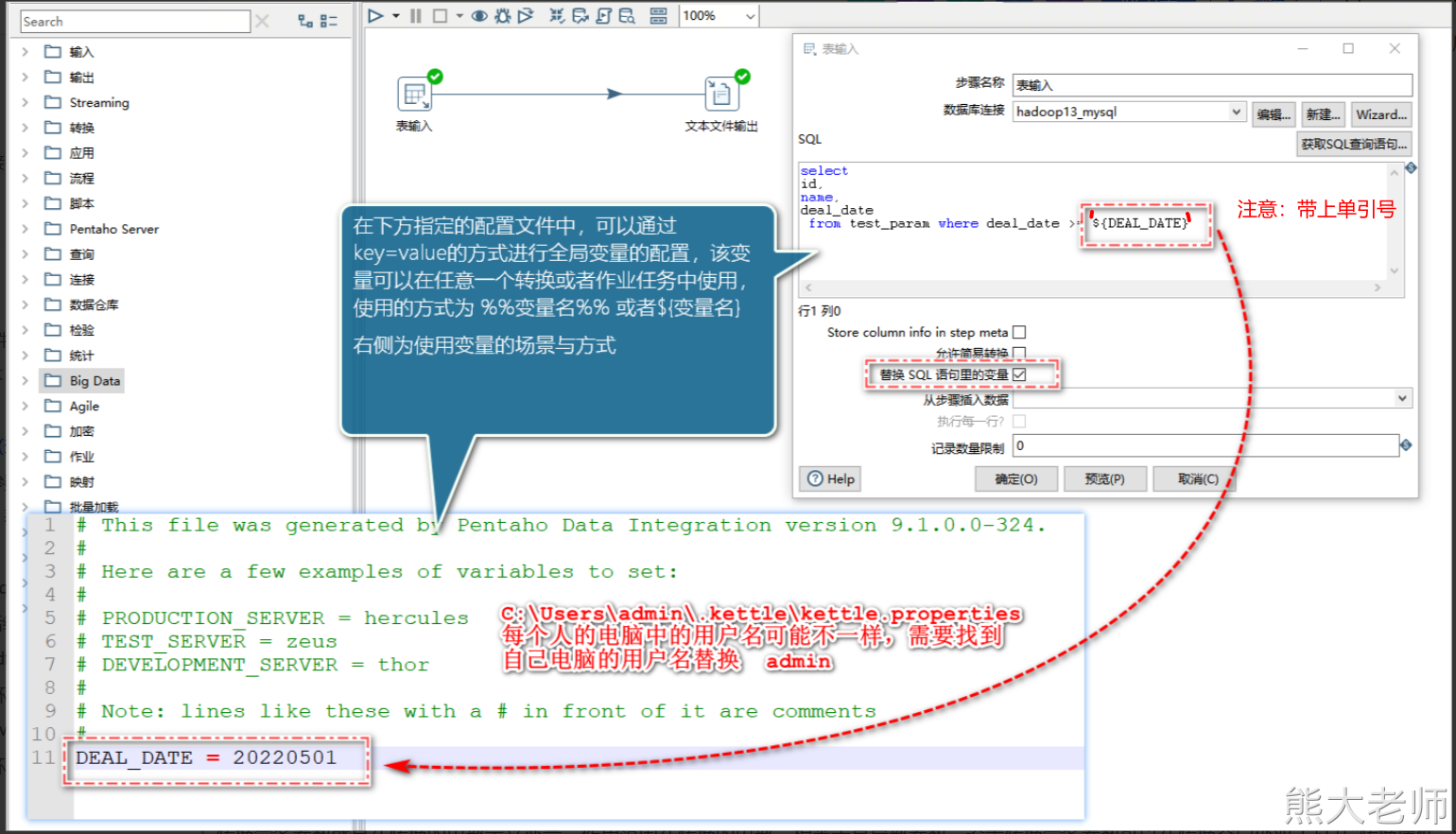
1) 全局参数(变量)
在ETL过程中可能需要一些预先定义好的参数,在ETL业务中可以使用这些参数。这些参数可以定义成全局参数。
全局参数定义是通过当前用户下.kettle目录中的kettle.properties文件来定义的,定义方式使用Key=Value方式,例如:ID=1。注意:在定义配置全局参数后需要重启Kettle才会生效。定义好的全局参数在任何转换和作业中可以直接使用。使用参数有两种方式:“%%变量名%%”和“${变量名}”。
在企业中,应用进行版本的迭代,数据的生成发生了变化,历史数据不再进行抽取处理,或者查询等操作
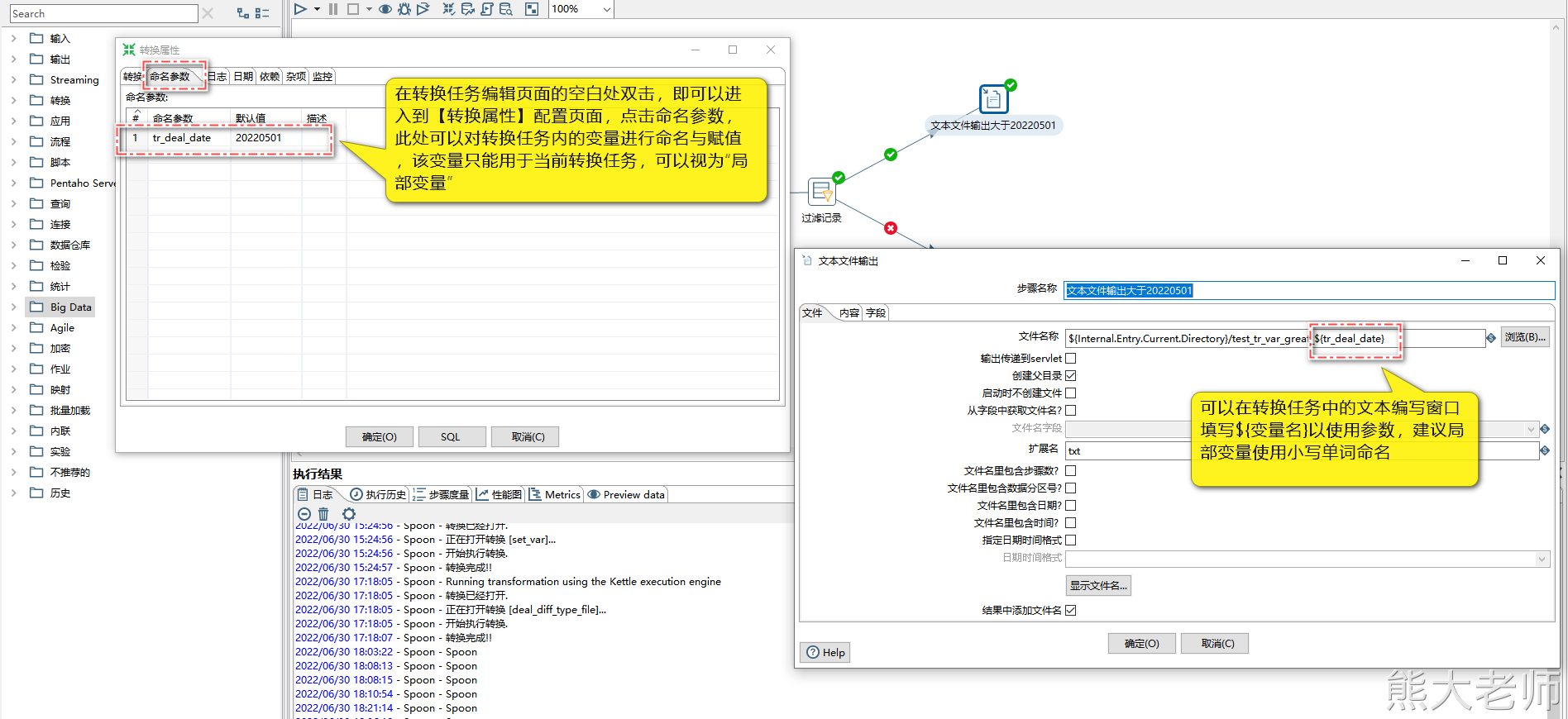
2) 转换命名参数(局部变量)
转换命名参数就是在转换的内部定义变量,作用范围在转换的内部,相当于是局部参数。设置转换命名参数可以在转换空白处双击打开“转换属性”->“命名参数”进行设置
3) 设置变量 / 获取变量
在转换中有“作业”分类,在里面有“设置变量”和“获取变量”的步骤,“设置变量”可以定义一些值,这些值不能在当前转换中使用,需要在下一个转换中使用,在下一个转换中通过“获取变量”来使用。
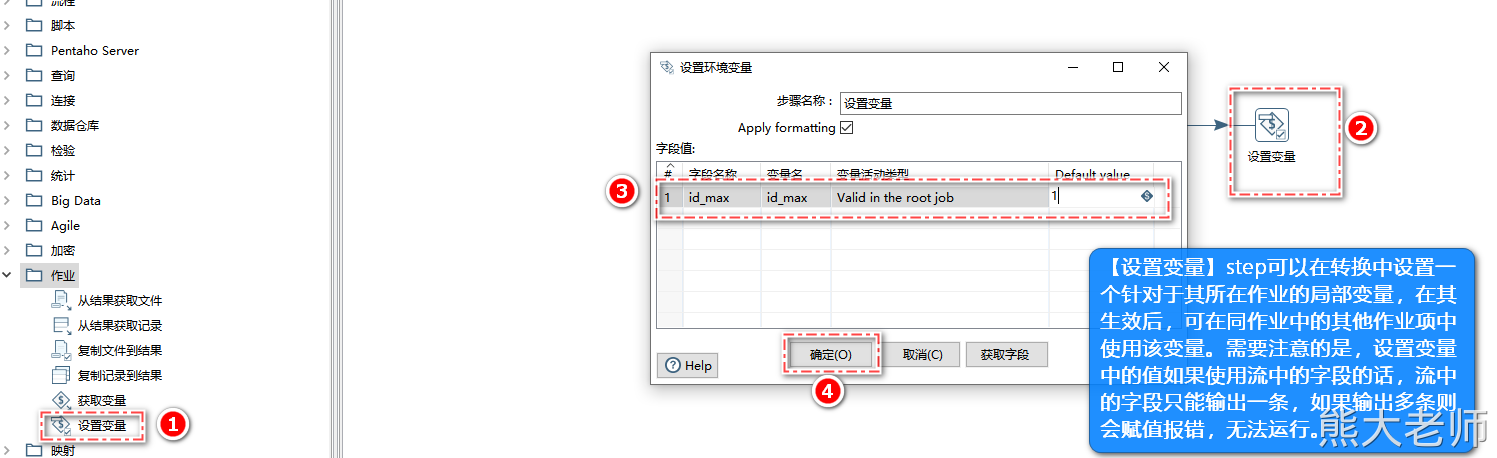
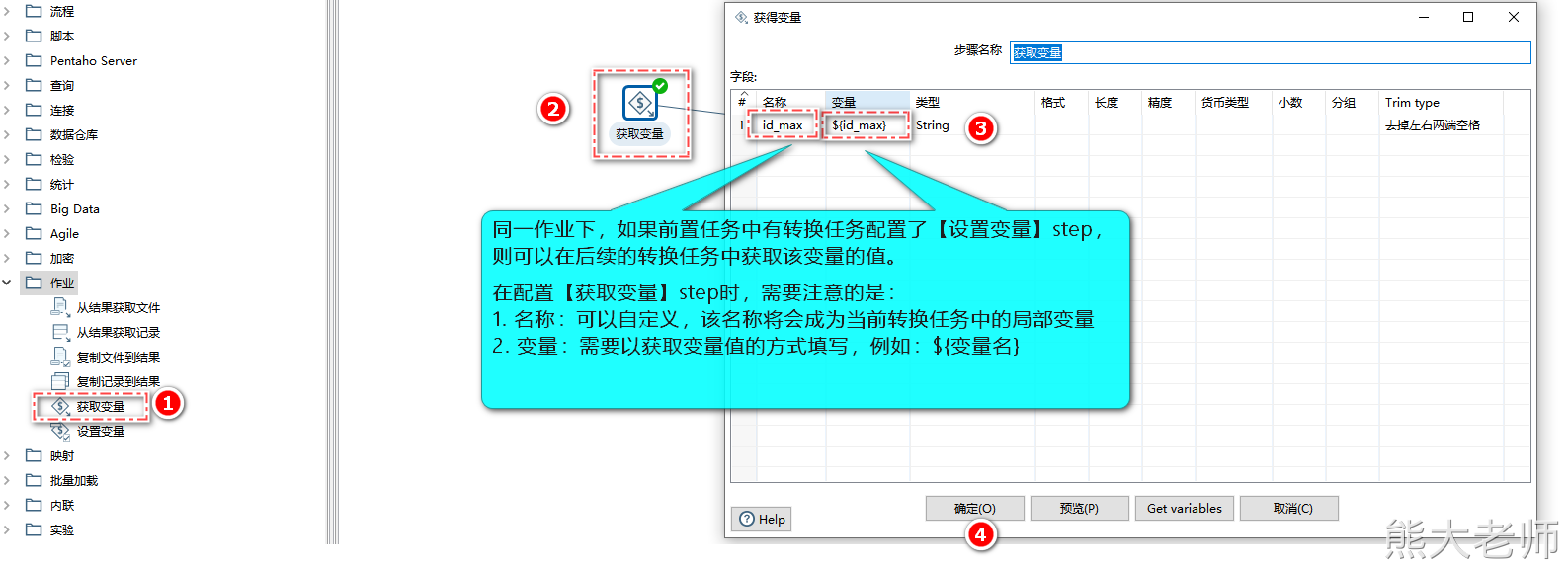
适用场景:
某业务系统,每日产生数据量过大,单个mysql库无法存放一日的完整数据,需要不同服务器上的两个数据库进行数据存放。
数据在中午12点开始进行存放位置切换,会同步向两个服务器中的mysql库进行insert,持续3分钟
在并行存放数据3分钟后,停止向即将存储满的第一台服务器中的mysql进行insert,此时数据只向第二台服务器中的mysql中插入数据。
需求:抽取全天数据,且保证数据的不重复
实现:在抽取完第一台服务器中mysql的表数据后,通过分组获取数据ID的最大值,并通过【设置变量】进行变量的设置,新建一个转换任务,在转换中使用【获取变量】对上一步转换设置的变量进行获取,然后将新增的局部变量放入SQL条件中(ID > ${最大值变量}),用来完成数据的范围限定,从而保证数据的不重复。
注意:在进行变量的设置与获取时,变量的名称应全程一致,不然在表输入中无法获取到变量的中的值。
八、整体案例
1. 批量采集mysql数据到文件中
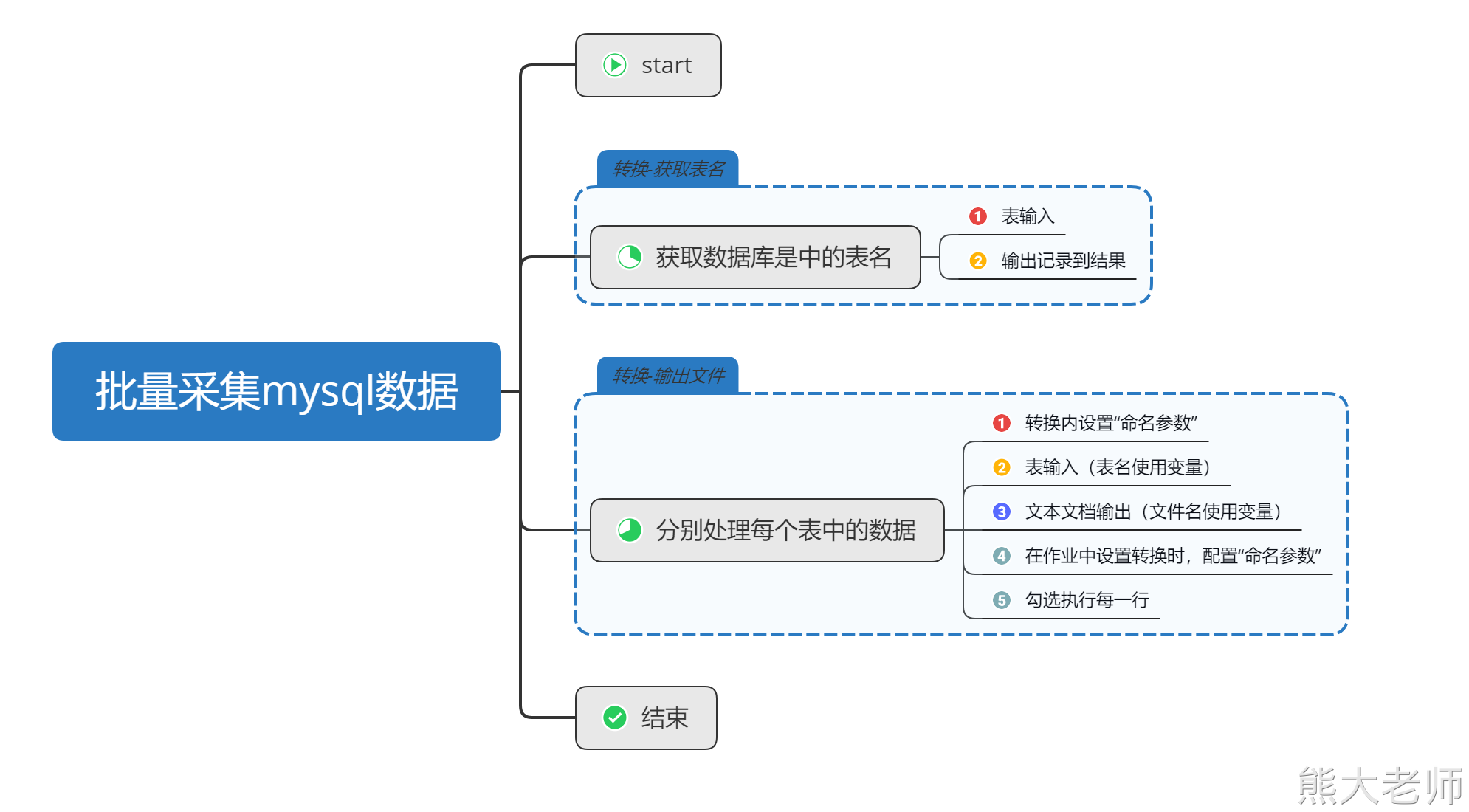
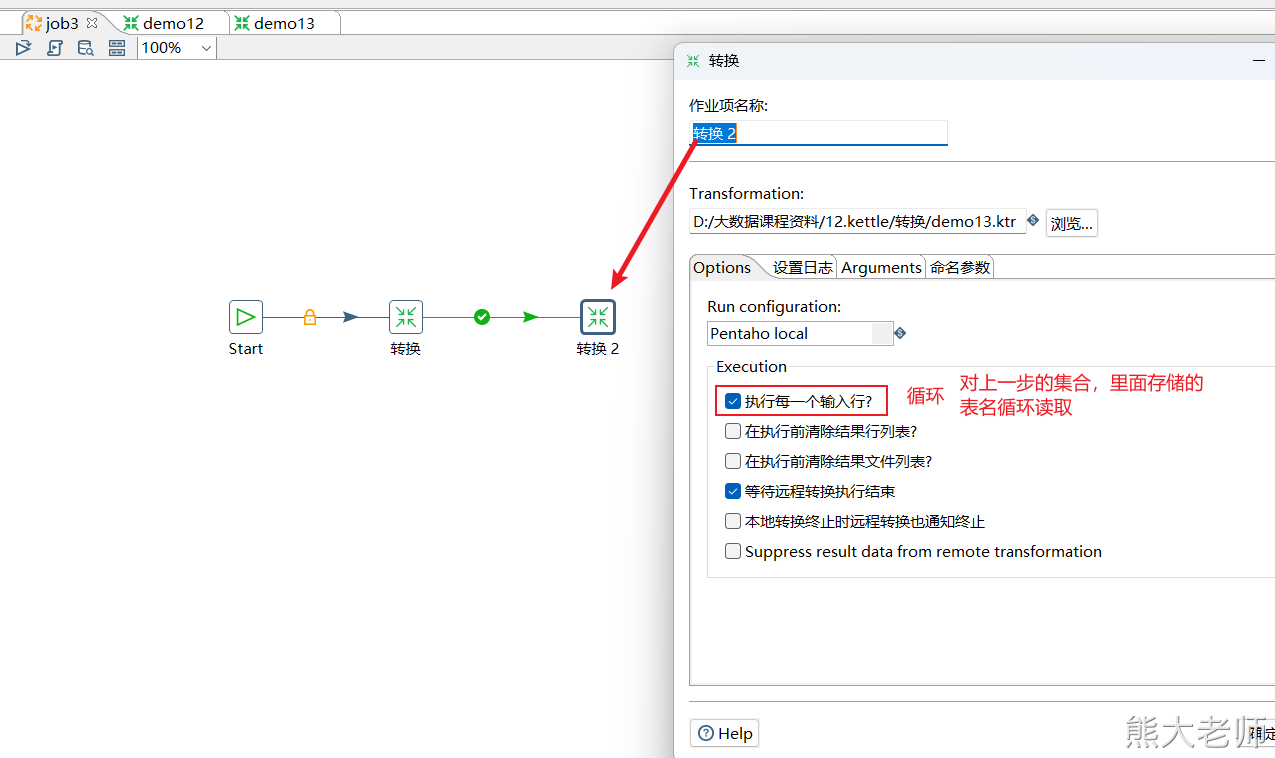
确认需求:将一个数据库中的所有表数据,全部输出到文件中,每个表生成一个以表名作为文件名的文件。
方案构思:
创建相应数量的转换任务,一个个执行。(可以但不推荐)
创建一个转换任务,不停的进行表名和文件的替换,然后重跑。(可以但不推荐)
有没有一种可能,可以让kettle进行循环
循环依据:将数据库中的表名放入一个数组,对数组进行循环
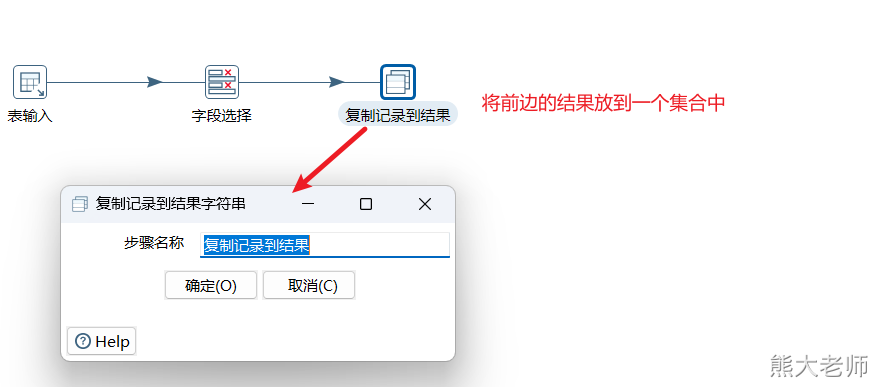
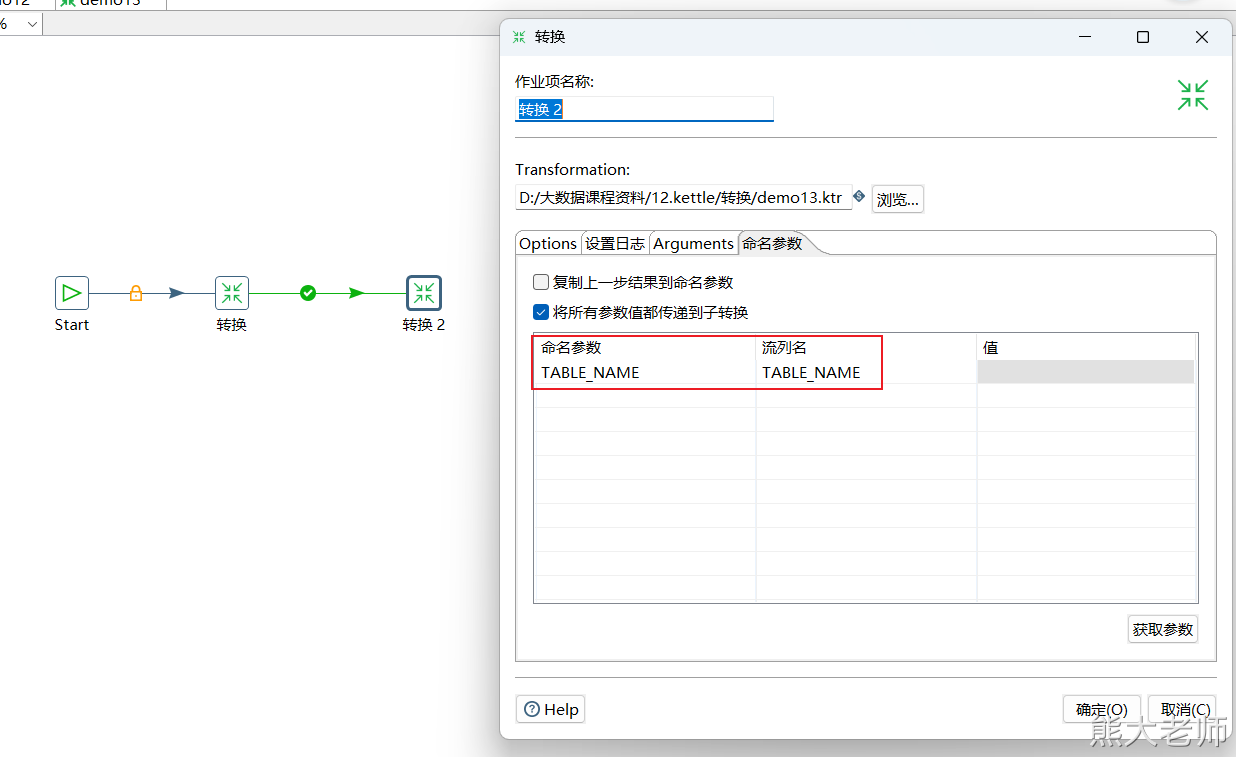
循环过程:每次从数组中获取一个表名,将这个表名放入两个地方,分别是表输入中的from后面的表名,与文本文件输出中的文件名。
调用起来,循环执行。
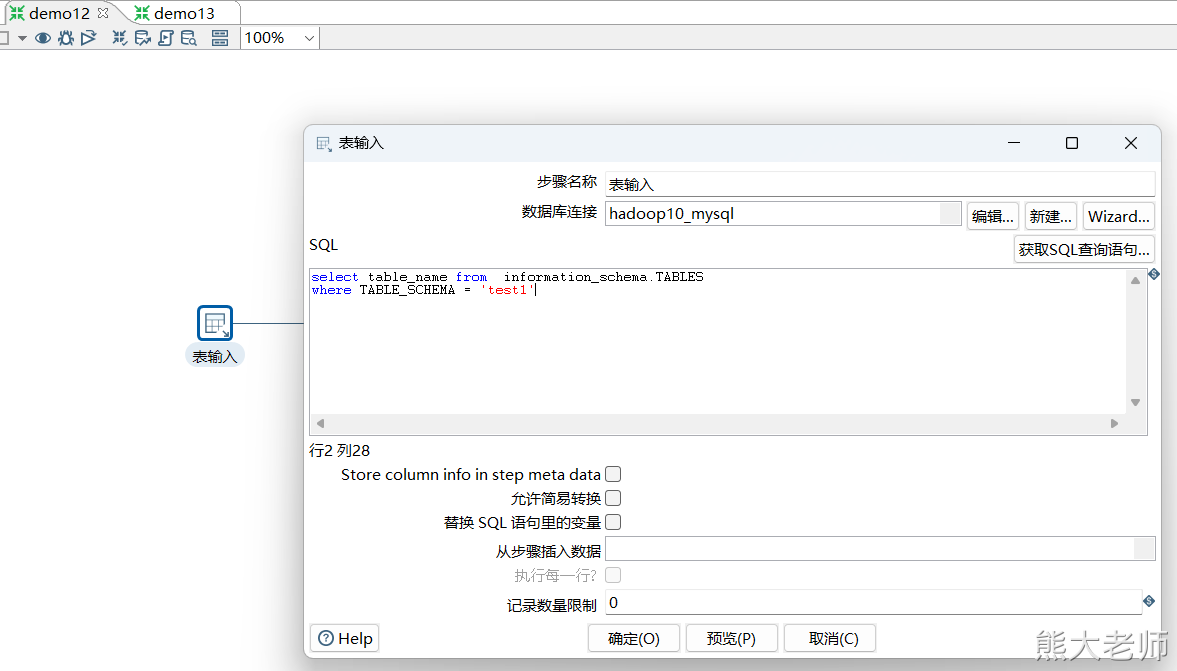
在需要获取数据库中的所有表名的时候,可以使用以下SQL语句进行查询:
select table_name from information_schema.TABLES where TABLE_SCHEMA = 'test1'
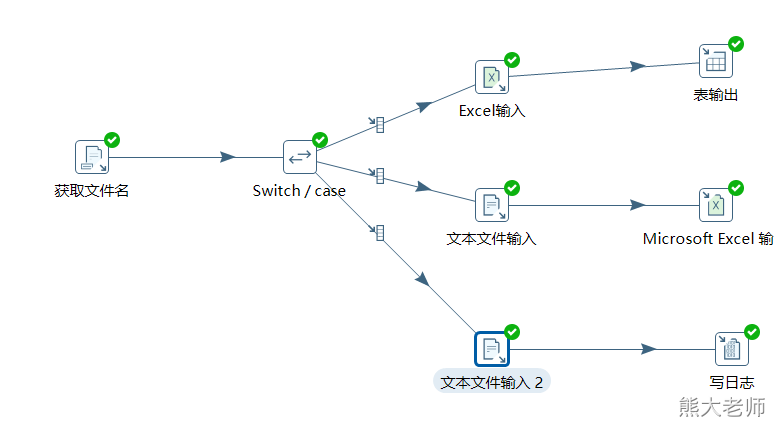
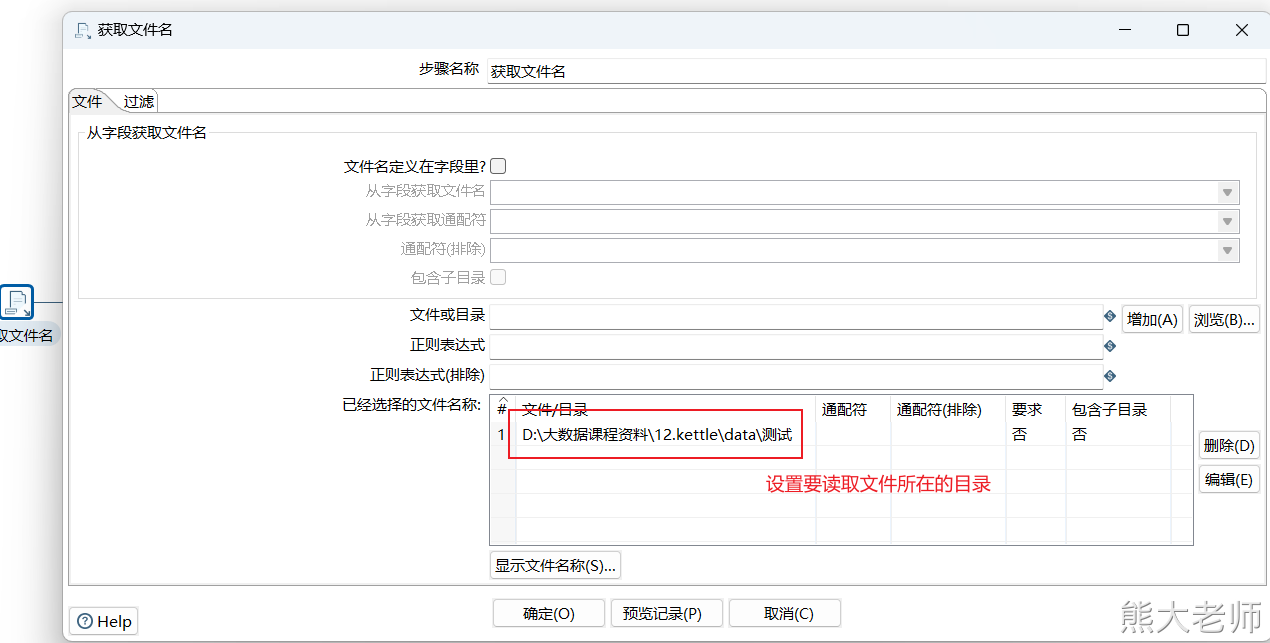
2. 根据文件的后缀不同,分别处理
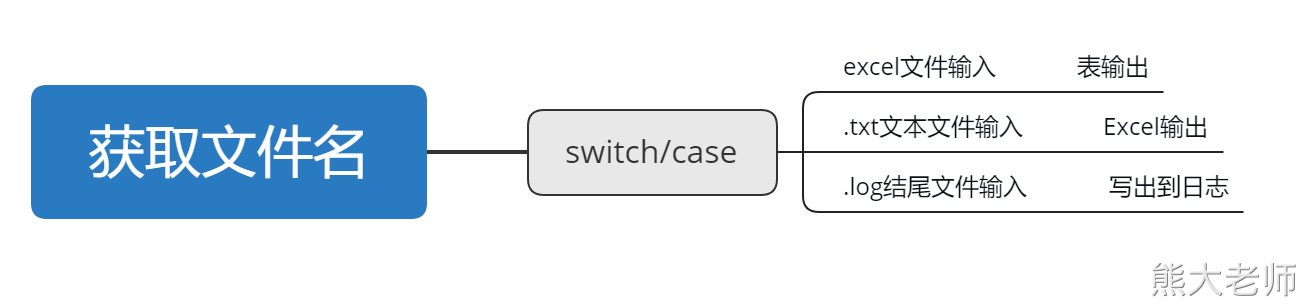
需求:在一个文件夹下有很多文件,且这些文件的后缀有多种,现在要求通过一个转换将文件中的数据分发不同的目的地
3. 输出数据到hdfs
1)配置hdfs环境
添加驱动:
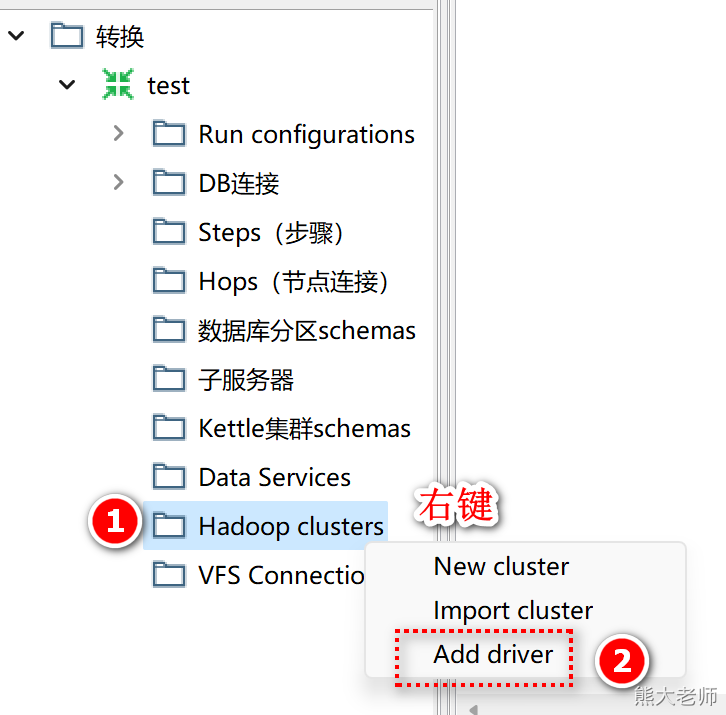
驱动位于“D:\pdi-ce-9.1.0.0-324\data-integration\ADDITIONAL-FILES\drivers”路径下:
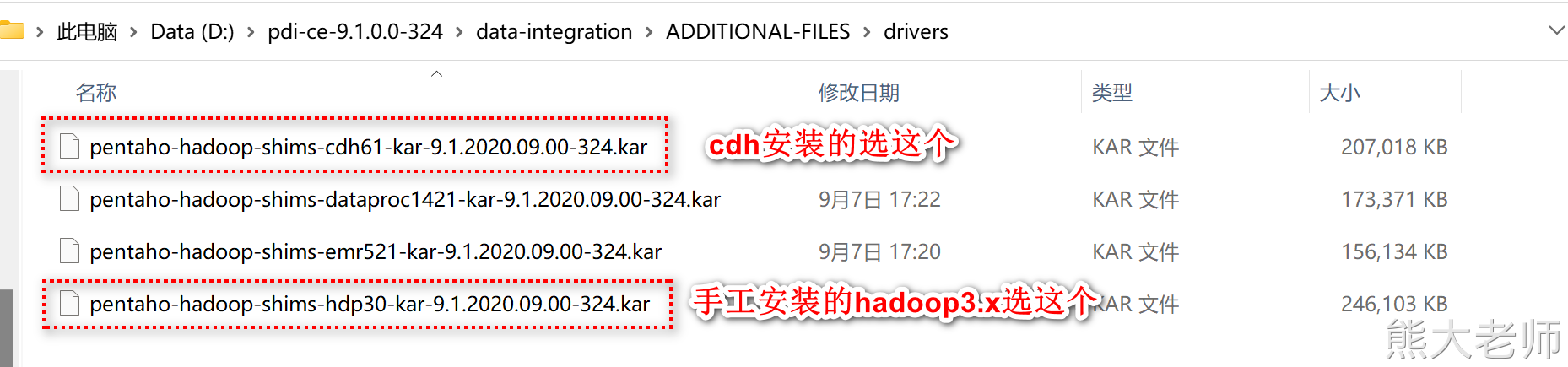
添加之后一定要重启Kettle
新建集群
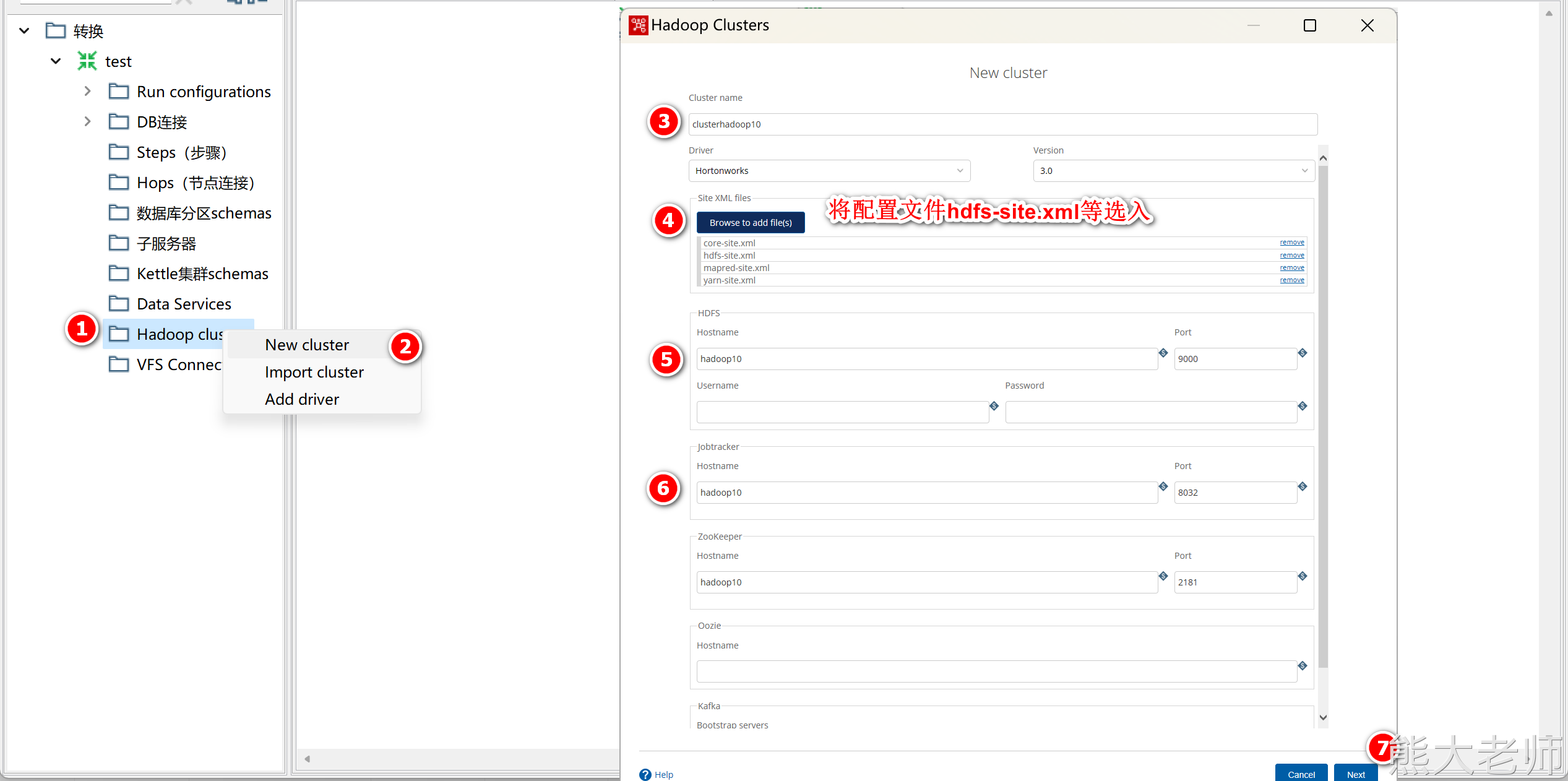
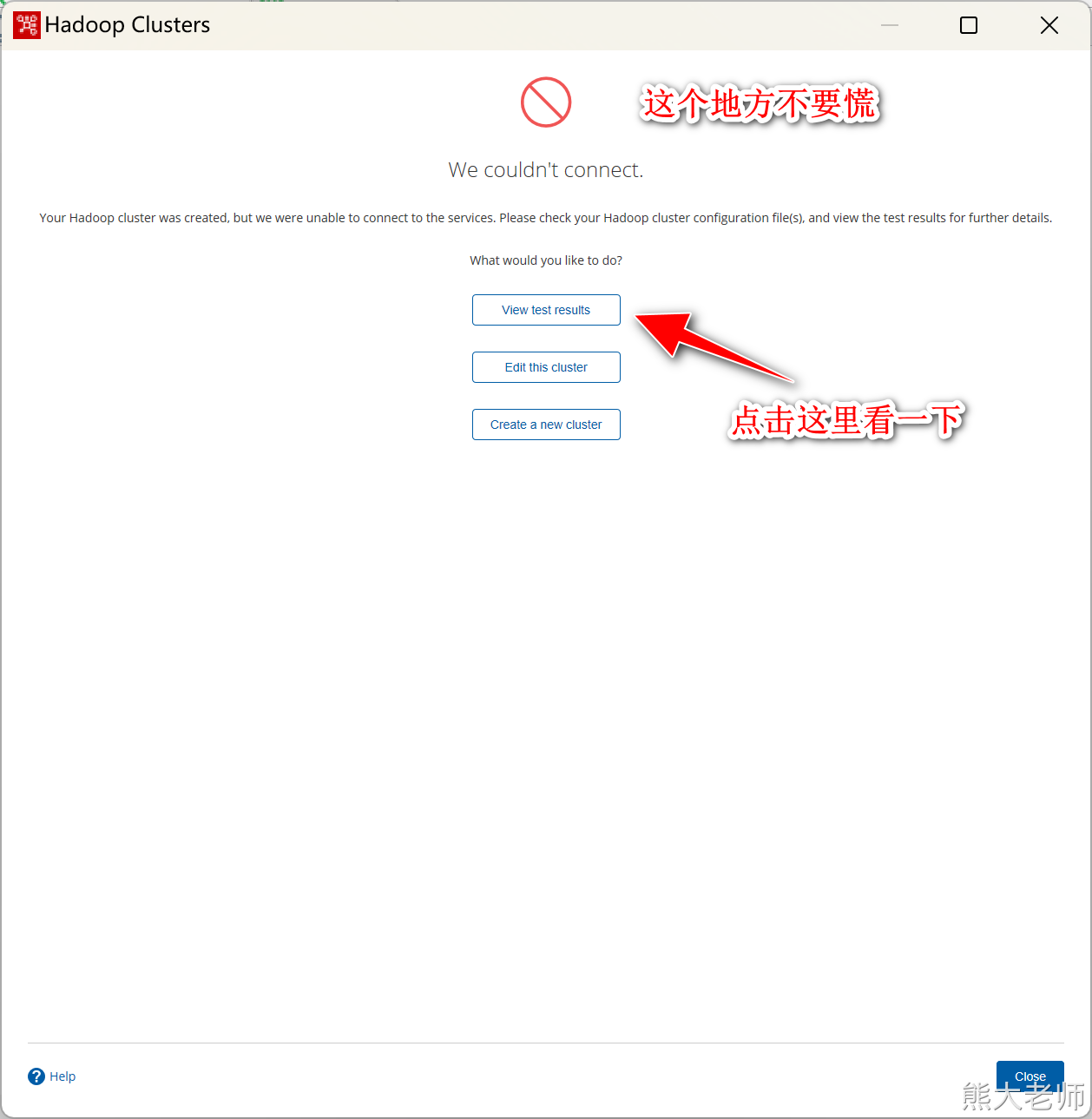
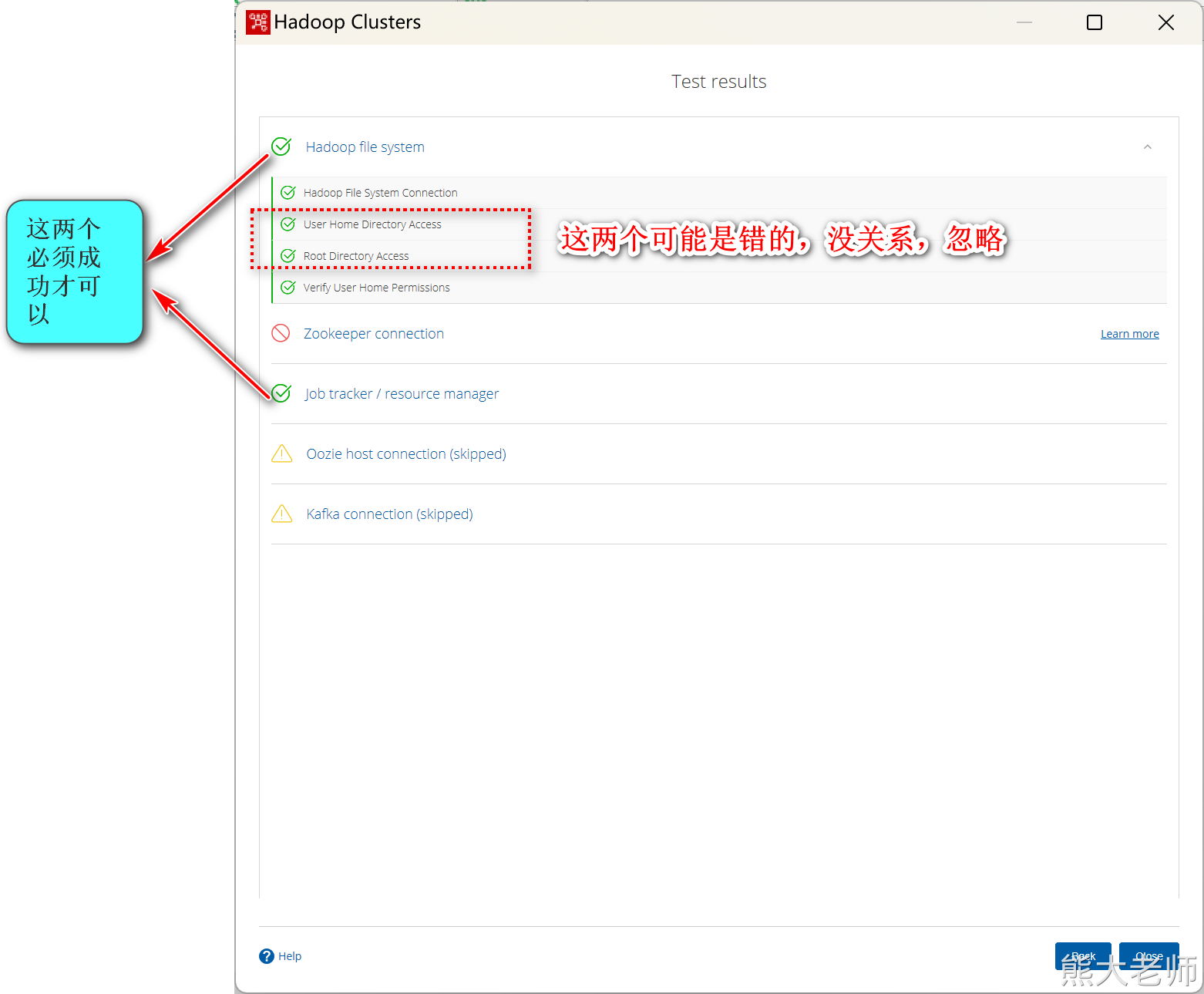
注意:如果在执行过程中出现编码问题可以修改“D:\pdi-ce-9.1.0.0-324\data-integration\Spoon.bat”文件第127行,添加以下内容,指定编码为UTF-8(注意添加时,有空格),添加后重启Kettle
"-DHADOOP_USER_NAME=root" "-Dfile.encoding=UTF-8"

如果在测试连接成功的情况下,还是无法在步骤中使用hdfs的step完成数据的抽取或者输出,则将两个地方的缓存文件夹删除即可:
C:\Users\admin.kettle
D:\BigData-2204\14.kettle\pdi-ce-9.1.0.0-324\data-integration\system\karaf\caches
注意:在抽取hdfs文件的时候,如果点击【获取字段】出现报错,需要变更文件的格式,具体如下:
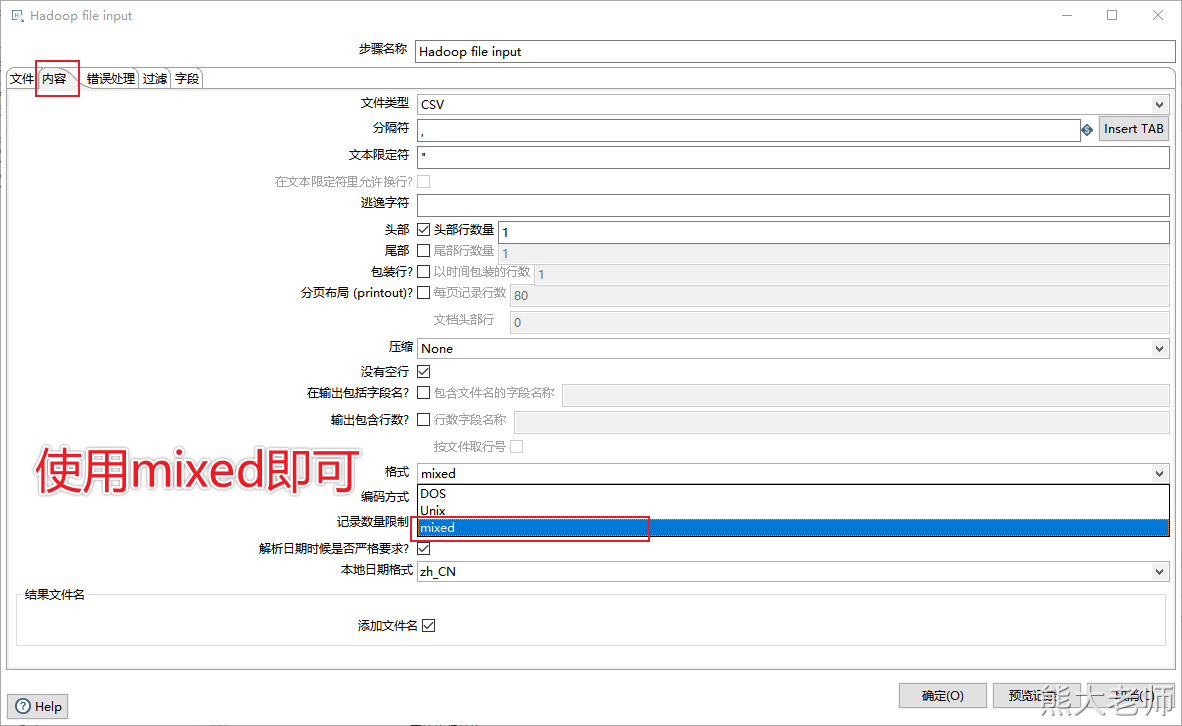
4. 输出数据到hive
1)配置hive环境
修改plugin.properties配置(根据自己安装目录)
进入D:\pdi-ce-9.1.0.0-324\data-integration\plugins\pentaho-big-data-plugin修改plugin.properties文件
# 这里指的是一个文件夹的名字,是相对路径 #D:\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations active.hadoop.configuration=hdp30
将hdfs-site.xml,core-site.xml,mapred-site.xml,hive-site.xml配置文件拷贝到此目录下(根据自己安装目录)
D:\pdi-ce-9.1.0.0-324\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp30
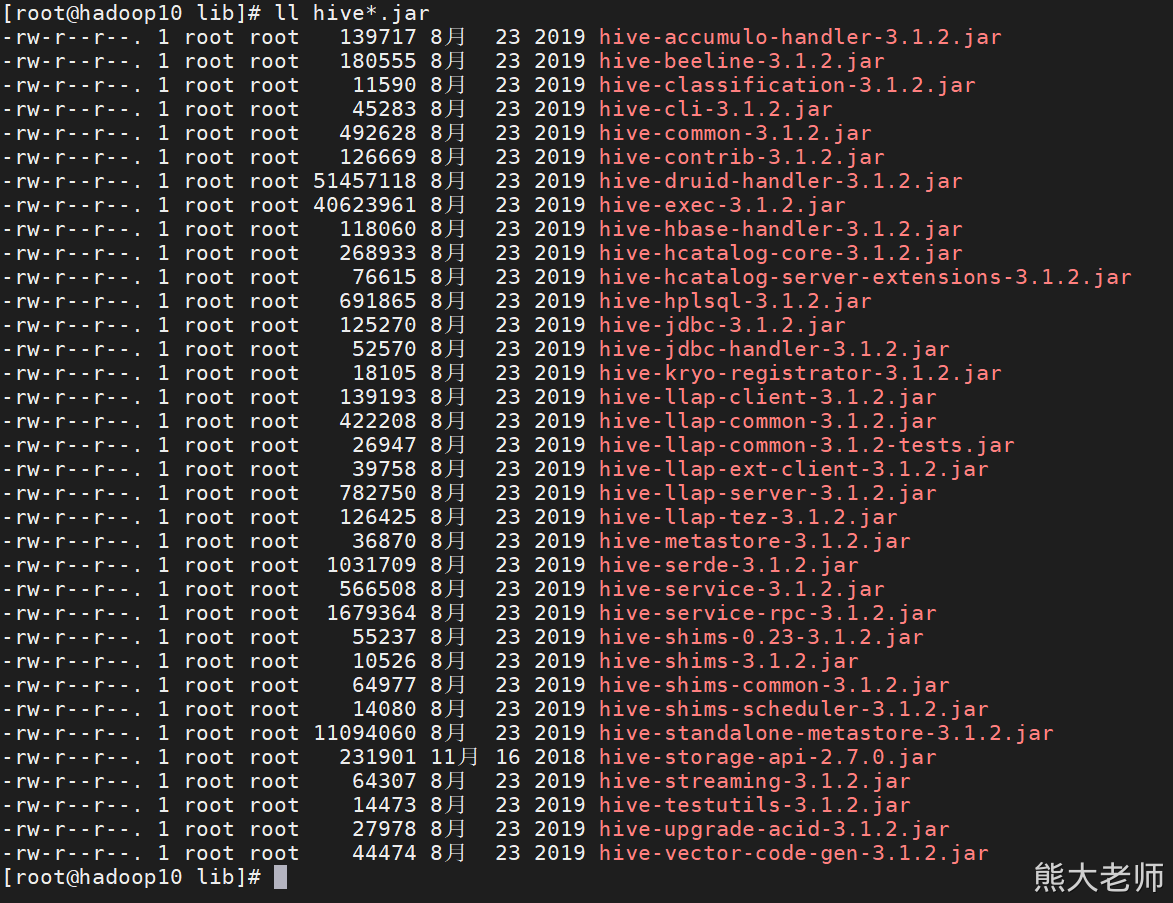
将以下Jar包放入D:\pdi-ce-9.1.0.0-324\data-integration\lib下,操作后,重启Kettle
hadoop-common-*.jar(在hadoop安装目录下 /opt/installs/hadoop3.1.4/share/hadoop/common 中)
hive-*.jar(在hive安装目录下lib中)
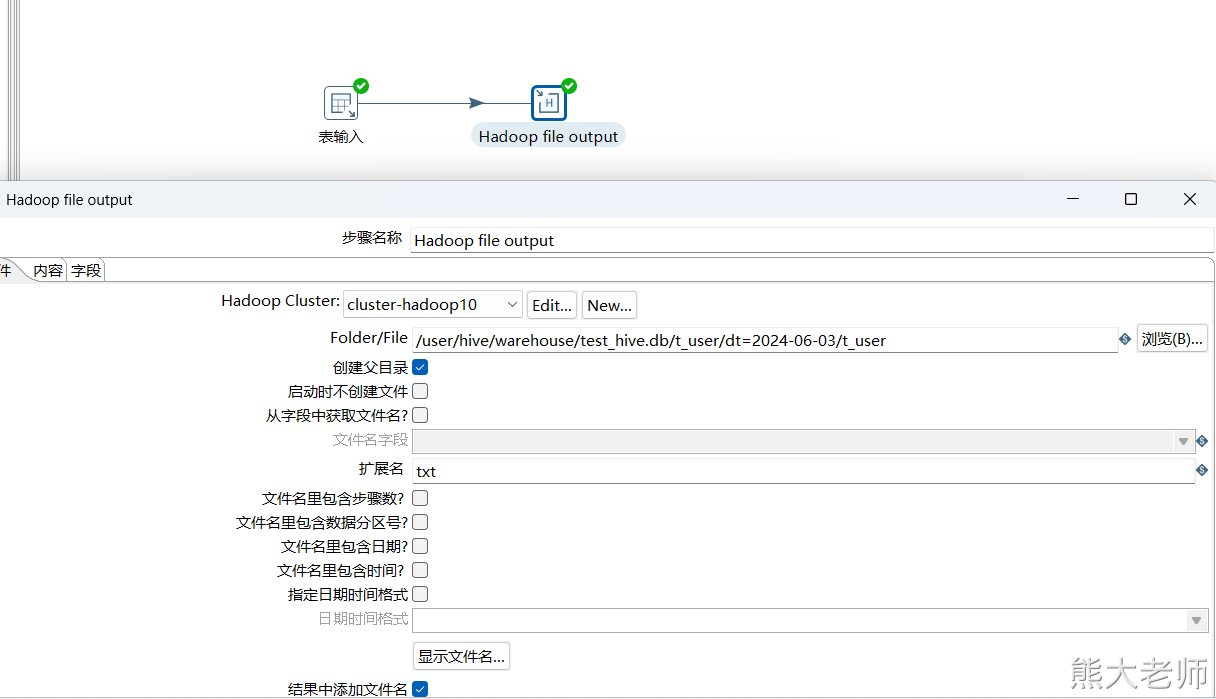
2)配置ETL
【表输入(MySQL)】--【表输出(hive)】